텐서플로 모델과 나머지 시스템을 분리할 수 있습니다.
텐서플로 서빙 사용하기

tf.keras 모델을 TF 서빙으로 배포할 때 먼저 해야할 일은 모델을 SavedModel 포맷으로 내보내는 것입니다.
model_version = '0001'
model_name = 'my_mnist_model'
model_path = os.path.join(model_name, model_version)
# tf.saved_model.save()
tf.saved_model.save(model, model_path)
tf.saved_model.save() 함수에 모델, 경로를 전달하면 그 경로에 모델의 계산 그래프와 가중치를 저장합니다. model.save(model_path)를 사용할 수도 있습니다.
CAUTION_
SavedModel이 계산 그래프를 저장하므로 텐서플로 연산만 사용한 모델에 적용할 수 있습니다. 또한 동적 tf.keras 모델은 계산 그래프로 변환할 수 없으니 제외됩니다. 동적 모델은 플라스크 등을 사용해 서빙되어야 합니다.
saved_model.pb에 계산 그래프가 정의되어 있고, variables 디렉터리에 변숫값이 저장됩니다. assets 디렉터리는 모델을 위한 샘플 데이터 같은 부가적인 데이터가 들어있습니다. 여기서는 assets 디렉터리를 사용하지 않습니다.
tf.saved_model.load() 함수를 사용해 SavedModel을 로드할 수 있습니다. 이 함수의 반환값은 케라스 모델이 아닌 계산 그래프와 변숫값을 담은 SavedModel객체입니다. 입력으로 적절한 타입의 텐서를 전달해야합니다.
saved_model = tf.saved_model.load(model_path)
y_pred = saved_model(tf.constant(X_new, dtype=tf.float32))
keras.models.load_model()로 케라스 모델로 직접 로드할 수 있습니다.
model = keras.models.load_model(model_path)
# model.save, tf.keras.models.save_model로 만들었을 때 사용 가능
y_pred = model.predict(X_new)
saved_model_cli 명령어로 SavedModel을 검사할 수 있습니다.
$ saved_model_cli show --dir my_mnist_model/0001 --all
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['__saved_model_init_op']:
The given SavedModel SignatureDef contains the following input(s):
The given SavedModel SignatureDef contains the following output(s):
outputs['__saved_model_init_op'] tensor_info:
dtype: DT_INVALID
shape: unknown_rank
name: NoOp
Method name is:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['flatten_input'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 28, 28, 1)
name: serving_default_flatten_input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['dense_1'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 10)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predict
Defined Functions:
Function Name: '__call__'
Option #1
Callable with:
Argument #1
inputs: TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='inputs')
Argument #2
DType: bool
Value: True
Argument #3
DType: NoneType
Value: None
Option #2
Callable with:
Argument #1
flatten_input: TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='flatten_input')
Argument #2
DType: bool
Value: True
Argument #3
DType: NoneType
Value: None
Option #3
Callable with:
Argument #1
flatten_input: TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='flatten_input')
Argument #2
DType: bool
Value: False
Argument #3
DType: NoneType
Value: None
Option #4
Callable with:
Argument #1
inputs: TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='inputs')
Argument #2
DType: bool
Value: False
Argument #3
DType: NoneType
Value: None
Function Name: '_default_save_signature'
Option #1
Callable with:
Argument #1
flatten_input: TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='flatten_input')
Function Name: 'call_and_return_all_conditional_losses'
Option #1
Callable with:
Argument #1
inputs: TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='inputs')
Argument #2
DType: bool
Value: False
Argument #3
DType: NoneType
Value: None
Option #2
Callable with:
Argument #1
flatten_input: TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='flatten_input')
Argument #2
DType: bool
Value: True
Argument #3
DType: NoneType
Value: None
Option #3
Callable with:
Argument #1
flatten_input: TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='flatten_input')
Argument #2
DType: bool
Value: False
Argument #3
DType: NoneType
Value: None
Option #4
Callable with:
Argument #1
inputs: TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='inputs')
Argument #2
DType: bool
Value: True
Argument #3
DType: NoneType
Value: None
SavedModel은 하나 이상의 메타그래프(metagraph)를 포함합니다. 하나의 메타 그래프는 하나의 계산 그래프와 함수 시그니처(function signature) 정의(입·출력 이름, 타입, 크기)입니다. 각 메타 그래프는 일련의 태그로 구분됩니다.
훈련 연산의 계산 그래프가 담긴 메타그래프는 'train' 태그를 가질 수 있습니다. 예측 연산만 있는 계산 그래프가 담긴 메타그래프는 'serve' 태그를 가질 수 있습니다.
초기화 함수(__saved_model_init_op)와 기본 서빙 함수(serving_default)의 시그니처 정의를 포함한 'serve' 태그된 메타그래프 하나를 저장합니다. 기본 서빙 함수(serving_default)는 예측을 만드는 모델의 call() 함수에 대응됩니다.
np.save('my_mnist_tests.npy', X_new)
$saved_model_cli run --dir my_mnist_model/0001
--tag_set serve \
--signature_def serving_default \
--inputs flatten_input=my_mnist_tests.npy
Result for output key dense_1:
[[5.0800870e-04 7.2780576e-06 4.5957789e-04 1.2992017e-03 3.2367103e-04
1.8232403e-04 1.3373331e-05 9.8598099e-01 3.0344265e-04 1.0922091e-02]
[2.4714902e-02 2.2193477e-03 7.2754383e-01 4.8869886e-02 6.8774541e-05
2.9350413e-02 1.2918028e-01 7.1388249e-06 3.7949488e-02 9.5876640e-05]
[5.2105746e-04 9.1797560e-01 2.3907347e-02 1.1499359e-02 2.6538703e-03
6.3670347e-03 8.6344648e-03 8.0806389e-03 1.7072113e-02 3.2885647e-03]]
3개의 샘플에서 각각 클래스 확률 10개를 출력합니다. SavedModel을 준비했으니 TF 서빙을 설치할 차례입니다.
텐서플로 서빙 설치하기
TF 서빙을 설치하는 방법은 많습니다. Doker 이미지를 사용하거나 시스템 패키지 매니저, 소스에서 설치하는 방법이 있습니다.
Docker를 사용해 host system을 훼손하지 않고 높은 성능을 제공할 수 있습니다. 공식 TF 서빙 도커 이미지를 다운로드합니다.
$ docker pull tensorflow/serving
이 이미지를 실행하기 위해 도커 컨테이너를 만듭니다.
$ docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v "$ML_PATH/my_mnist_model:/models/my_mnist_model" \
-e MODEL_NAME=my_mnist_model \
tensorflow/serving
명령줄 옵션이 의미하는 것은 다음과 같습니다.
- -it : interactive 모드로 컨테이너를 만듭니다.(Ctrl + C를 눌러 중지시킬 수 있습니다.) 서버의 출력을 화면에 나타냅니다.
- --rm : 중지될 때 컨테이너를 삭제합니다. (중지된 컨테이너 때문에 시스템이 지저분해지지 않습니다.) 하지만 이미지를 삭제하지 않습니다.
- -p 8500:8500 : 도커 엔진이 TCP 포트 8500번을 컨테이너의 TCP 포트 8500번으로 포워딩합니다. 기본적으로 TF 서빙은 이 포트를 사용해 gRPC API를 제공합니다.
- -p 8501:8501 : 호스트 시스템의 TCP 포트 8501번을 컨테이너의 TCP 포트 8501번으로 포워딩합니다. 기본적으로 TF 서빙은 이 포트를 사용해 REST API를 제공합니다.
- -v "MLPATH/mymnistmodel:/models/mymnistmodel":호스트시스템의ML_PATH/my_mnist_model:/models/my_mnist_model 디렉터리를 컨테이너의 /models/mnist_model 경로에 연결합니다. Windows에서는 호스트 경로의 '/'를 '\'로 바꾸어야합니다.
- -e MODEL_NAME=my_mnist_model : TF 서빙이 어떤 모델을 서빙할지 알 수 있도록 컨테이너의 MODEL_NAME 환경 변수를 설정합니다. 기본적으로 /models 디렉터리에서 모델을 찾고 자동으로 최신 버전을 서비스합니다.
- tensorflow/serving : 실행할 이미지 이름입니다.
파이썬에서 이 서버를 호출해보겠습니다. 방법이 REST API, gRPC API 2가지 있습니다.
REST API로 TF 서빙에 쿼리하기
input_data_json = json.dumps({
'signature_name': 'serving_default',
'instances': X_new.tolist()
})
'''
'{"signature_name": "serving_default", "instances": [[[[0.0], [0.0], [0.0], [...]
0.3294, 0.7254, [..very long], 0.0, 0.0, 0.0, 0.0]]]}'
'''
이 입력 데이터를 HTTP POST 메서드로 TF 서빙에 전송해봅시다. requests 라이브러리를 사용해 처리할 수 있습니다. 표준 라이브러리는 아니므로 pip으로 먼저 설치해야합니다.
import requests
SERVER_URL = 'http://localhost:8501/v1/models/my_mnist_model:predict'
response = requests.post(SERVER_URL, data=input_data_json)
response.raise_for_status() # 에러가 생길 경우 예외를 발생합니다.
response = response.json()
응답은 'predictions' 키 하나를 가진 딕셔너리입니다. predictions 키의 값은 예측의 리스트입니다. 이 리스트는 파이썬 리스트이므로 넘파이 배열로 바꿉니다.
y_proba = np.array(response['predictions'])
y_proba.round(2)
'''
array([[0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.99, 0. , 0.01],
[0.02, 0. , 0.73, 0.05, 0. , 0.03, 0.13, 0. , 0.04, 0. ],
[0. , 0.92, 0.02, 0.01, 0. , 0.01, 0.01, 0.01, 0.02, 0. ]],
dtype=float32)
'''
예측을 얻을 수 있습니다. goorm ide는 docker를 지원 안해줘서 못했습니다.. 일단 정리만
REST API는 입·출력 데이터가 너무 크지 않으면 잘 작동합니다. 또한 대부분의 클라이언트 애플리케이션이 다른 것에 의존하지 않고 REST API를 사용할 수 있습니다.
반면에, JSON 기반이므로 텍스트를 사용하고 매우 장황합니다. 예를 들어 ndarray를 python의 list로 변환하면 모든 실수가 문자열로 표현됩니다. 이는 모든 실수와 문자열 간의 변환을 위해 직렬화/역직렬화한다는 측면에서 payload 크기 면에서 매우 비효율적입니다. 많은 실수가 15개 문자로 표현됩니다. 32비트 실수를 120 비트로 변환한 셈입니다. 큰 넘파이 배열을 전송할 때 응답 속도를 느리게 하고 네트워크 대역폭을 많이 사용합니다.
TIP
대량의 데이터를 전송할 땐 gRPC API를 사용하는 게 좋습니다. 컴팩트한 이진 포맷과 (HTTP/2 frame에 기반한) 효율적인 통신 프로토콜을 사용하기 때문입니다.
REST API도 REST 요청 전에 먼저 데이터를 직렬화하고 Base64로 인코딩하여 이를 완화할 수 있습니다. gzip을 사용해 REST 요청을 압축하면 페이로드 크기를 줄일 수 있습니다.
gRPC API로 TF 서빙에 쿼리하기
gRPC API는 직렬화된 PredictRequest 프로토콜 버퍼를 입력으로 기대합니다. 직렬화된 PredictResponse 프로토콜 버퍼를 출력합니다. 이 프로토콜은 tensorflow-serving-api에 포함되어 있습니다. pip을 사용해 라이브러리를 설치해야합니다.
from tensorflow_serving.apis.predict_pb2 import PredictRequest
request = PredictRequest()
request.model_spec.name = model_name
request.model_spec.signature_name = 'serving_default'
input_name = model.input_names[0]
request.inputs[input_name].CopyFrom(tf.make_tensor_proto(X_new))
PredictRequest 프로토콜 버퍼를 만들고 필수 필드를 채웁니다. 필수 필드에는 모델 이름, 호출할 함수 시그니처 이름, Tensor 프로토콜 버퍼 형식으로 변환한 입력 데이터가 포함됩니다. tf.make_tensor_proto() 함수는 주어진 텐서나 ndarray을 기반으로 Tensor 프로토콜 버퍼를 만듭니다.
앞서 서버로 요청을 보냈으니 응답을 받습니다. (grpcio 라이브러리를 pip를 사용해 설치할 수 있습니다.)
import grpc
from tensorflow_serving.apis import prediction_service_pb2_grpc
channel = grpc.insecure_channel('localhost:8500')
predict_service = prediction_service_pb2_grpc.PredictionServiceStub(channel)
response = predict_service.Predict(request, timeout=10.0)
localhost에서 TCP 포트 8500번으로 gRPC 통신 채널을 만듭니다. 이 채널로 gRPC 서비스를 만들고 10초 타임아웃이 설정된 요청을 보냅니다.(응답을 받거나 타임 아웃이 지날 때까지 멈춰있을 것입니다.) 여기서는 보안 채널을 사용하지 않지만 gRPC와 TF-serving SSL/TLS 기반의 보안 채널도 제공합니다.
PredictResponse 프로토콜 버퍼를 텐서로 바꾸어보겠습니다.
output_name = model.output_names[0]
outputs_proto = response.outputs[output_name]
y_proba = tf.make_ndarray(outputs_proto)
이 코드를 y_proba.numpy().round(2)를 출력하면 앞에서와 동일한 클래스 추정 확률을 얻을 수 있스빈다. 몇 줄 코드만으로 REST나 gRPC를 사용해 텐서플로 모델을 원격에서 접속할 수 있습니다.
새로운 버전의 모델 배포하기
model = keras.models.Sequential([...])
model.compile([...])
history = model.fit([...])
model_version = '0002'
model_name = 'my_mnist_model'
model_path = os.path.join(model_name, model_version)
tf.saved_model.save(model, model_path)
앞에서와 같이 my_mnist_model/0002 디렉터리에 SavedModel을 내보내겠습니다. 일정한 간격으로 텐서플로 서빙이 새로운 버전을 확인합니다. 간격은 조정할 수 있습니다. 새로운 버전을 찾으면 버전 교체를 진행합니다. 대기중인 요청은 이전 버전에서 응답하고, 대기중인 요청이 모두 내려가면 이전 버전 모델은 내려갑니다. 새로운 요청은 새 버전에서 처리합니다. 텐서플로 서빙 로그에서 이 작업을 확인할 수 있습니다.
이 방법은 버전 전환을 부드럽게 처리하지만, RAM을 많이 사용합니다. (특히 GPU RAM) 해결 방법으로 새 버전의 모델을 로드하고 사용하기 전에 대기중인 모든 요청을 이전 모델로 처리하고 삭제하도록 설정할 수 있습니다. 버전 2 모델이 잘 작동하지 않는다면 간단히 my_mnist_model/0002 를 삭제하여 버전 1로 롤백(rollback)할 수 있습니다.
TIP
TF 서빙의 자동 배치기능은 여러 클라이언트의 요청을 받아 모델을 사용하기 전에 이 요청들을 자동으로 배치로 만들어줍니다. 이 기능은 시작 시 --enable_batching 옵션으로 활성화할 수 있습니다. 배치 지연 시간을 증가시키면 응답 속도를 희생하고 높은 처리 능력을 얻을 수 있습니다. --batching_parameters_file 옵션을 참고하세요.
초당 쿼리 요청이 많다면 TF 서빙을 서버 여러대에 설치하고 쿼리를 로드 밸런싱해야 합니다.
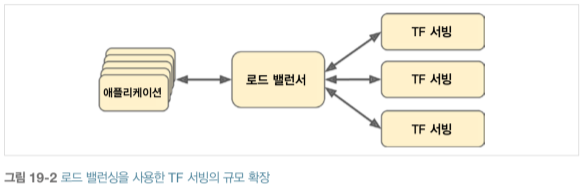
많은 TF 서빙 컨테이너를 서버에 배포하고 관리해야 합니다. 이를 해결하는 한 가지 방법은 Kubernetes를 사용하는 것입니다. 쿠버네티스는 많은 서버의 컨테이너를 관리할 수 있는 오픈 소스입니다. 클라우드 플랫폼에 있는 가상 서버를 사용하면 쉽게 서버를 사용할 수 있습니다. 가상 서버를 관리하고 쿠버네티스의 도움을 받아 컨테이너를 운영하고 TF 서빙을 설정하고 튜닝, 모니터링하려면 전담 인력이 필요합니다.
이 장에서는 구글 클라우드 AI 플랫폼을 사용해 MNIST 모델을 클라우드에서 서비스해보겠습니다. 아마존 AWS SageMaker나 마이크로소프트 AI 플랫폼과 같이 텐서플로 모델을 서빙할 수 있는 다른 서비스도 존재합니다.
GCP AI 플랫폼에서 예측 서비스 만들기

GCP 계정이 생성될 때 'My First Project'라는 프로젝트가 만들어집니다. IAM 및 관리자 → 설정에서 프로젝트 이름을 수정한 후 저장합니다. 만들 때 프로젝트 ID를 정할 수 있지만 나중에는 바꿀 수 없습니다. 프로젝트 번호는 자동으로 생성되고 바꿀 수 있습니다.
CAUTION_
몇 시간만 필요한 서비스라면 나중에 중지해야합니다. 몇 달 동안 실행되도록 나두면 엄청난 비용이 청구될 수 있습니다.
GCP 계정을 준비했으면 서비스를 사용할 수 있습니다. 먼저 필요한 것은 GCS(Google Cloud Storage)입니다. 메뉴에서 저장소 → 브라우저를 클릭합니다. 하나 또는 여러 개 버킷(bucket)에 모든 파일을 저장할 것입니다.
버킷 만들기를 클릭한 후 버킷 이름을 입력합니다. (먼저 Storage API를 활성화해야 합니다.) 이 버킷 이름은 DNS 레코드로 사용될 수 있으니 DNS 이름 규칙에 맞는지 확인해야합니다. 버킷이 위치할 지역을 선택하고 나머지 옵션은 기본값으로 둔 후 만들기 버튼을 누릅니다.
앞서 만든 my_mnist_model 폴더를 버킷에 업로드합니다. (GCS 브라우저 화면에서 이 버킷을 클릭하고 시스템에 있는 my_mnist_model 폴터를 버킷으로 드래그 앤 드롭합니다.)

이전 까지는 ML Engine이었고, 이제 사용할 모델, 버전을 지정하기 위해 AI 플랫폼을 설정합니다. 메뉴에서 인공지능 → AI Platform → 모델을 클릭합니다. API 사용 설정을 클릭하고 모델 만들기를 클릭한 후 상세 정보를 입력합니다. 그 다음 만들기를 클릭합니다.
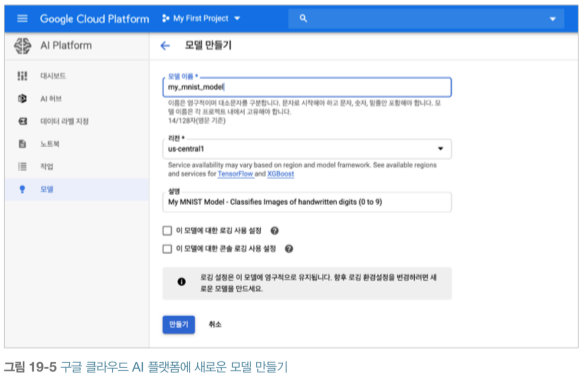
AI 플랫폼에 모델이 준비되었으므로 모델 버전을 만들고, 모델 리스트에서 방금 만든 모델을 클릭한 후 버전 만들기를 누르고 상세 정보를 입력합니다. 여기에서 ML 런타임 버전, GCS에 있는 모델 경로 (예를 들면, gs://my-mnist-model-bucket/my_mnist_model/0002/) 등을 설정합니다. 확장에서 자동 확장을 선택합니다. 이는 항상 실행될 TF 서빙 컨테이너의 최소 개수입니다. 이 필드는 비워둡니다. 그 다음 저장을 누릅니다.

처음으로 클라우드에 모델을 배포했습니다. 축하합니다.!!! 자동 확장을 선택했기 때문에 초당 쿼리수(QPS)가 늘어나면 AI 플랫폼이 TF 서빙 컨테이너를 더 많이 실행하고 쿼리를 로드 밸런싱할 것입니다.
NOTE
예측 서비스를 사용하지 않으면 AI 플랫폼이 모든 컨테이너를 중지할 것입니다. 이 경우 사용한 스토리지 양만 비용으로 청구됩니다. GB 당 월 요금은 몇 십원 정도입니다. 이 서비스에 쿼리 요청을 걸리면 AI 플랫폼이 TF 서빙 컨테이너를 시작해야 해서 몇 초 정도 걸립니다. 이런 지연이 발생하지 않아야 한다면 모델 버전을 만들 때 TF 서빙 컨테이너 최소 개수를 1로 설정해야 합니다. 이렇게 하면 머신 하나가 계속 실행되므로 월 요금은 더 많이 청구될 것입니다.
이제 이 예측 서비스에 쿼리해봅시다.
예측 서비스 사용하기
AI 플랫폼은 TF 서빙을 할 뿐이므로 쿼리할 URL을 알고 있다면 앞에서와 동일한 코드를 사용할 수 있습니다. 다만, GCP는 SSL/TLS 기반 암호와와 인증 토큰이 필요합니다. 요청마다 인증 토큰이 서버로 전달되어야 합니다.
먼저 인증 설정을 하고 애플리케이션에 GCP 상 권한을 부여해야합니다. 인증 옵션은 2개가 있습니다.
- 애플리케이션에 사용자 인증 정보(credential), 즉 구글 아이디로 인증할 수 있습니다. 사용자 인증 정보를 사용하면 애플리케이션이 GCP에서 동일한 권한을 가집니다. 이 방식은 대부분 필요하지 않습니다.
- 클라이언트 코드는 서비스 계정(service account)으로 인증할 수 있습니다. 이 계정은 사용자가 아니라 애플리케이션을 나타내는 계정으로 매우 제한된 접근 권한을 부여합니다.
애플리케이션을 위한 서비스 계정을 만들어봅시다. 메뉴에서 IAM 및 어드민 → 서비스 계정 → 서비스 계정 만들기를 누른 후 정보를 채우고 일부 권한을 줍니다. ML Engine 개발자 역할을 선택합니다. 이 역할의 서비스 계정은 예측을 만들 수 있지만, 그 외의 권한은 거의 없습니다. 또는 같은 조직에 속한 사용자를 서비스 계정의 권한을 사용할 수 있도록 허가할 수 있습니다.
그 다음 서비스 계정의 개인 키를 JSON 형태로 선택해 만듭니다.

구글 API 클라리언트 라이브러리
OAuth와 REST 기반 가벼운 라이브러리입니다. AI 플랫폼을 비롯한 GCP 서비스에 사용할 수 있습니다.
pip install google-api-python-client
구글 클라우드 클라이언트 라이브러리
조금 더 고수준 라이브러리입니다. GCS, 구글 빅쿼리, 구글 클라우드 자연어, 구글 클라우드 비전같은 특정 서비스를 위한 전용 라이브러리입니다. 가령, GCS 클라이언트 라이브러리는 아래와 같습니다.
pip install google-cloud-storage
구글 API 보다 구글 클라우드 라이브러리가 성능을 높이기 위해 REST 대신 gRPC를 사용하기 때문에 클라우드 클라이언트 라이브러리를 이용하는 것이 좋습니다.
책을 쓸 당시 AI 플랫폼을 구현한 클라우드 라이브러리가 없어서 구글 API 클라이언트 라이브러리를 사용하겠습니다. 이 라이브러리는 서비스 계정의 개인 키를 사용해야 합니다. GOOGLE_APPLCATION_CREDENTIALS 환경 변수를 설정해 개인 키 파일 위치를 알려줄 수 있습니다.
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = 'my_service_account_key.json'
NOTE_
구글 클라우드 엔진(GCE)의 가상 머신이나 구클 클라우드 쿠버네티스 엔진을 사용한 컨테이너 안에 배포하거나 GOOGLE Cloud App Engine에서 웹 애플리케이션으로 또는 구글 클라우드 함수의 마이크로서비스로 애플리케이션을 배포할 때 GOOGLE_APPLICATION_CREDENTIALS 환경 변수를 설정하지 않으면 이 라이브러리는 해당 서비스의 기본 서비스 계정을 사용합니다.(ex, GCE에서 실행된다면 기본 GCE 서비스 계정입니다.)
그 다음 예측 서비스 접근을 감싼 리소스 객체(resource object)를 만들어야 합니다.
import googleapiclient.discovery
project_id = 'onyx-smoke-242003' # 이 값을 자신의 프로젝트 ID로 바꾸세요
model_id = 'my_mnist_model'
model_path = 'project/{}/models/{}'.format(project_id, model_id)
ml_resource = googleapiclient,discovery.build('ml', 'v1').projects()
google.apiengine 모듈을 찾을 수 없다는 에러가 난다면 build() 메서드를 호출할 때 cache_discovery=False로 지정하세요.
model_path에 /versions/0001을 추가해 쿼리할 버전을 지정할 수 있습니다. 그 다음 리소스 객체를 사용해 예측 서비스를 호출하고 결과를 반환하는 함수를 작성하겠습니다.
def predict(X):
input_data_json = {'signature_name': 'serving_default',
'instances': X.tolist()}
request = ml_resource.predict(name=model_path, body=input_data_json)
response = request.execute()
if 'error' in response:
raise RuntimeError(response['error'])
return np.array([pred[output_name] for pred in response['predictions']])
이 함수는 입력 이미지를 담은 넘파이 배열을 받아 딕셔너리 하나를 만듭니다. 클라이언트 라이브러리는 이 딕셔너리를 JSON 포맷으로 변환한 다음 예측 요청을 준비하고 실행합니다. 에러가 발생하지 않으면 각 샘플에 대한 예측을 추출하여 넘파이 배열로 만듭니다.
Y_probas = predict(X_new)
np.round(Y_probas, 2)
'''
array([[0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.99, 0. , 0.01],
[0.02, 0. , 0.73, 0.05, 0. , 0.03, 0.13, 0. , 0.04, 0. ],
[0. , 0.92, 0.02, 0.01, 0. , 0.01, 0.01, 0.01, 0.02, 0. ]],
dtype=float32)
'''
성공했다면 클라우드에서 실행되는 예측 서비스를 만든 것입니다. 이 서비스는 QPS 값에 따라 자동으로 규모를 늘릴 수 있고 안전하게 쿼리할 수 있습니다. 사용하지 않는다면 청구되는 비용도 거의 없습니다. Google Stackdriver를 사용해 자세한 로그와 측정 자료를 얻을 수도 있습니다.
모바일 또는 임베디드 장치에 모델 배포하기
모바일, 임베디드 장치에 모델을 배포할 때는 경량인 모델이 필요합니다. TFLite 라이브러리를 이용해 모델을 경량화할 수 있습니다. 경량화에는 3가지 목표가 있습니다.
- 다운로드 시간, RAM 사용량을 줄이기 위해 모델 크기를 줄입니다.
- 응답 속도, 배터리 사용량, 발열을 줄이기 위해 예측에 필요한 계산량을 줄입니다.
- 모델을 장치의 제약 조건(spec)에 맞춥니다.
TFLite의 모델 변환기는 SavedModel → FlatBuffers 기반의 경량 포맷으로 압축합니다. TFLite는 플랫폼에 독립적인 직렬화(serialization) 라이브러리입니다. FlatBuffers는 전처리 없이 RAM으로 바로 로드됩니다. 이는 로드에 걸리는 시간, 메모리 사용을 줄입니다. 모델이 모바일, 임베디드 장치에 로드되면 TFLite 인터프리터가 이 모델을 실행해 예측을 만듭니다.
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_path)
tflite_model = converter.convert()
with open('converted_model.tflite', 'wb') as f:
f.write(tflite_model)
Tip
from_keras_model()을 사용해 tf.keras 모델을 바로 FlatBuffers로 저장할 수도 있습니다.
변환기가 크기도 줄이고 지연 시간도 줄이기 위해 모델 최적화를 수행합니다. 예측에 필요하지 않은 훈련 연산 등을 삭제하고 가능한 연산을 최적화합니다. 예를 들어, 3*a+4*a+5*a → (3+4+5)*a로 변환될 것입니다. 또한, 가능하면 연산을 결합시키는데, 가령 배치 정규화 층을 이전 층에 덧셈 연산과 곱셈 연산으로 합칠 수 있습니다.
TFLite가 얼마나 모델을 최적화할 수 있는지 시각적으로 보려면, TFLite 모델(https://homl.info/litemodels) 하나를 다운 받고 Netron(https://lutzroeder.github.io/netron)에 접속해 .pb 파일을 업로드하고 원본 모델을 확인해보세요. 크고 복잡한 그래프가 나올 것입니다. 다음으로 최적화된 .tflite 모델을 업로드 한 후 확인해보면 훨씬 simple한 그래프가 나올 것입니다.
모델 크기를 줄이는 또 다른 방법에는 더 작은 비트 길이를 사용하는 것이 있습니다. 32bits → 16bits를 사용하면 정확도를 조금 잃고 모델의 크기를 2배로 줄일 수 있습니다. 훈련 속도가 빨라지고 GPU RAM 사용량이 거의 절반으로 줄어들 것입니다.
TFLite는 모델의 가중치를 32bits float → 8bits integer로 압축합니다. 가장 간단한 방법은 훈련 후 양자화(post-training quantization)입니다. 훈련이 끝난 후 가중치를 양자화합니다. 가령, 가중치 범위가 -1.5 ~ +0.8이면 바이트 값 -127, 0, +127은 실수 -1.5, 0.0, +1.5에 각각 대응됩니다. 대칭 양자화를 사용하므로 0.0은 항상 0에 매핑되고 +0.8보다 큰 수에 매핑된 값(+68 ~ +127)은 사용되지 않습니다.
[그림 19-8]
post-training quantization을 수행하려면 convert() 메서드를 수행하기 전 OPTIMIZE_FOR_SIZE를 변환기 최적화 리스트에 추가하면 됩니다.
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
양자화된 가중치를 사용하려면 다시 부동소수로 바꾸어야합니다. 이 변환을 매번 수행하지 않기 위해 복원된 부동소수를 캐시하면 해당 RAM 사용량이 줄어들지 않습니다.
응답 지연, 전력 소모를 줄이는 가장 효과적인 방법은 활성화 출력도 양자화하는 것입니다. 이는 모든 계산을 정수로 수행할 수 있습니다. 동일한 비트 길이의 계산은 부동 소수보다 정수 계산이 CPU를 더 적게 사용합니다.
Edge TPU같은 신경망 가속 장치는 정수만 처리할 수 있어서 가중치 & 활성화 값을 모두 양자화하는 것은 필수적입니다. 최대 활성화 절댓값을 찾으려면 보정(calibration) 단계가 필요한데, 훈련 데이터에서 대표 샘플을 조금 전달해서 이 데이터를 모델에 통과시키고 양자화를 위해 필요한 활성화 통계를 측정합니다.
양자화의 주요 문제점은 정확도를 약간 희생하는 것입니다. 정확도 손실이 너무 크면 양자화를 고려한 훈련(quantization-aware training)이 필요할 수 있습니다. 모델을 훈련할 때 가짜 양자화 연산을 추가하여 훈련하는 동안 양자화 잡음에 대응하는 법을 배울 수 있습니다. 최종 가중치는 양자화에 더 안정적일 것이고, 보정 단계는 훈련하는 동안 자동으로 처리될 수 있어 전체 과정을 간소화할 수 있습니다.
TFLite로 앱, 임베디드 프로그램을 만드는 법을 알고 싶다면 TinyML(https://homl.info/tinyml)을 참고하세요.
브라우저를 위한 텐서플로
웹사이트에 있는 모델을 사용자가 브라우저에서 직접 실행할 수도 있습니다. 가령 아래와 같은 상황에서 유용합니다.
- 사용자의 인터넷 연결이 느리거나 자주 끊길 경우
- 모델의 응답 속도가 빨라야할 때: 예측을 만들기 위해 서버로 쿼리를 보내는 응답 지연을 줄입니다.
- 사생활 보호를 원할 때: 개인정보 데이터가 사용자 PC를 벗어나지 않습니다.
이런 모든 경우를 대비해 TensorFlow.js 자바스크립트 라이브러리에서 로드할 수 있는 포맷으로 모델을 변환할 수 있습니다. SavedModel이나 keras model을 TensorFlow.js 층 형태로 변환할 수 있는 tensorflowjs_converter 도구를 사용하면 됩니다. 여러 개로 나뉜 이진 포멧의 가중치 파일, 모델의 구조를 표현하고 가중치 파일을 연결하는 model.json 파일을 담은 디렉터리는 웹에서 효율적으로 다운받을 수 있도록 최적화되어 있습니다.
다음 코드를 보면 이 자바스크립트 API가 어떤 형태인지 알 수 있습니다.
import * as tf from '@tensorflow/tfjs';
const model = await tf.loadLayersModel('https://example.com/tfjs/model.json');
const image = tf.fromPixels(webcamElement);
const prediction = model.predict(image);
TensorFlow.js에 대해 자세히 배우고 싶다면 Practical Deep Learning for Cloud, Mobile, and Edge (https://homl.info/tfjsbook)을 참고하세요
계산 속도를 높이기 위해 GPU 사용하기
하나의 머신에 GPU 카드를 4개를 사용하는 것이 여러 머신에서 GPU 8개를 사용하는 것보다 일반적으로 신경망을 빠르게 훈련할 수 있습니다. 분산 환경의 네트워크 통신으로 발생하는 추가적인 지연 때문입니다. GPU를 준비하는 방법에는 직접 구입하는 방법과 클라우드에서 GPU가 장착된 가상 머신을 사용하는 방법이 있습니다.
GPU 구매하기
GPU 카드를 구매한다면 https://homl.info/66이 선택에 도움이 될 수 있습니다. 이 책을 쓰는 시점에서 tensorflow는 CUDA 계산능력(compute capability) 3.5 이상의 엔비디아 카드(https://homl.info/cudagpus)만 지원합니다. 당연히 구글 TPU도 가능합니다. 현재 시점에서 어떤 장치를 지원하는지 확인하려면 텐서플로 문서(https://www.tensorflow.org/install)를 참고하세요.
엔비디아 GPU 카드를 사용하려면 엔디비아 드라이버 몇 개와 라이브러리 몇개를 설치해야합니다. CUDA(compute unified device architecture) 라이브러리는 그래픽 가속 뿐 아니라 모든 종류의 연산에 대해 CUDA 지원 GPU를 사용하기 위해 필요합니다. cuDNN(CUDA deep neural network)은 DNN을 위한 저수준 GPU 가속 라이브러리입니다. cuDNN은 활성화 층, 정규화, 정방향과 역방향 합성곱, 풀링 같이 널리 사용되는 DNN 연산을 최적화하여 구현했습니다. 이 라이브러리는 엔비디아 딥러닝 SDK에 포함되어 있습니다.
이 라이브러리를 다운받으려면 엔비디아 개발자 계정을 만들어야합니다. (CUDA는 https://developer.nvidia.com/cuda-downloads에서, cuDNN은 https://developer.nvidia.com/rdp/cudnn-download에서 다운로드할 수 있습니다.) 텐서플로에 따라 버전이 다를 수 있어서 텐서플로 설치 문서를 확인하세요.
텐서플로는 CUDA, cuDNN을 사용해 GPU 카드를 제어하고 계산 속도를 높입니다.

GPU 카드 구매 후 필요한 드라이버, 라이브러리를 설치한 후 아래 명령어를 통해 CUDA 가 적절히 설치되었는지 확인할 수 있습니다.
$ nvidia-smi
텐서플로 GPU 버전도 설치해야합니다.(tensorflow-gpu 라이브러리) 텐서플로는 필요한 라이브러리를 모두 설치한 Docker 이미지를 제공합니다. 하지만 도커 컨테이너가 GPU를 사용하려면 여전히 호스트 머신에 엔비디아 드라이버를 설치해야 합니다.
텐서플로가 GPU를 잘 인식하는지 확인하려면 다음 명령으로 테스트해보세요.
import tensorflow as tf
# 적어도 하나의 GPU라도 사용 가능한 지
tf.test.is_gpu_available()
# 첫 번째 GPU 이름을 반환
tf.test.gpu_device_name()
# 사용 가능한 모든 GPU 장치 리스트를 반환
tf.config.experimental.list_physical_devices(device_type='GPU')
GPU를 장착한 가상 머신 사용하기
주요 클라우드 플랫폼은 모두 GPU VM을 제공합니다. GCP는 글로벌, 리전마다 GPU 할당 제한이 있습니다.
기본적으로 글로벌 GPU 할당량은 0이므로 어떤 GPU VM도 사용할 수 없습니다. GCP 콘솔에서 메뉴를 누르고 'IAM 및 관리자 → 할당량'으로 이동합니다. '측정항목'을 클릭 후 '선택해제'를 클릭해 모든 측정항목을 선택 해제합니다. 그 다음 'GPU'를 검색해 'GPUs (all regions)'를 선택합니다. 왼쪽의 체크 박스를 클릭하고 '할당량 수정'을 클릭합니다. 필요한 정보를 채우고 '요청 제출'을 클릭합니다.
기본적으로 리전마다 GPU 종류마다 하나의 GPU 할당량이 있습니다. 이 할당량도 요청할 수 있습니다. '측정항목'을 클릭 후 '선택해제'를 클릭해 모든 측정항목을 선택 해제합니다. 그 다음 'GPU'를 검색해 필요한 GPU Type을 고릅니다.(ex, NVIDIA P4 GPUs) 그 다음 위치 드롭 다운 메뉴에서 '선택 해제'를 클릭해 모든 위치를 선택 해제한 후 원하는 위치를 클릭합니다. 할당량의 왼쪽 박스를 체크하고 '할당량 수정'을 클릭하여 요청합니다.
GPU 할당량 요청이 승인되면 구글 클라우드 AI 플랫폼의 딥러닝 VM 이미지를 사용해 여러 GPU를 가진 VM을 만들 수 있습니다. https://homl.info/dlvm에서 'Console로 이동' → 'Compute Engine에서 실행'을 클릭 후 VM 설정 양식을 채웁니다. 위치에 따라 어떤 GPU는 지원되지 않는 경우도 있으니 위치를 바꾸면서 가능한 종류를 확인합니다. 프레임 워크는 Tensorflow 2.0, 'Install NVIDIA GPU driver automatically on first startup'을 체크합니다. 또한, 'Enable access to JupyterLab via URL instead of SSH'를 체크하는 것이 좋습니다. 이 GPU VM에서 JuputrtLab을 통해 주피터 노트북을 매우 쉽게 사용할 수 있습니다. VM이 만들어지면 메뉴 '인공지능' 섹션에서 'AI Platform → 노트북'을 클릭합니다. 노트북 인스턴스를 열어서 원하는 코드를 실행할 수 있습니다.
코랩
코랩은 구글 Docs 처럼 노트북을 사용하고 공유할 수 있습니다. 특별한 주석으로 편리한 폼(https://homl.info/colabforms)을 만들 수 있습니다.
코랩 노트북을 열 때 Colab Runtime(무료 구글 VM)에서 실행됩니다. 기본적으로 이 런타임은 CPU만 사용하는데, '메뉴 → 런타임 → 런타임 유형 변경'을 클릭하고 '하드웨어 가속기 → GPU'를 선택한 다음 '저장'을 클릭합니다. TPU를 선택할 수도 있습니다.
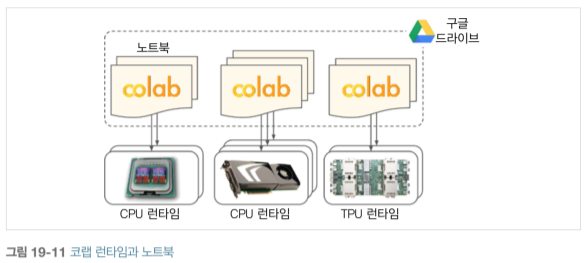
COLAB은 12시간 이후에는 자동으로 종료됩니다. 그럼에도 불구하고 간편하게 테스트하고 빠르게 결과를 얻고 동료와 협업할 수 있는 훌륭한 도구입니다. Colab Pro는 더 많은 메모리, GPU가 장착된 VM을 제공하고 최대 24시간 동안 실행할 수 있습니다.
GPU RAM 관리하기
기본적으로 텐서플로는 처음 계산할 때 자동으로 가능한 GPU의 모든 RAM을 확보합니다. 이는 GPU RAM의 단편화를 막기 위해서입니다. 다른 텐서플로 프로그램을 시작하면 금방 RAM 부족 현상이 발생합니다. 일반적으로 훈련 script 1개, TF serving node 1개 or jupyter 노트북 1개입니다. 어떤 이유로 프로그램 여러 개를 실행할 경우 (가령, 한 PC에서 다른 모델 2개를 훈련하는 경우) 프로세스 간에 균등하게 GPU RAM을 나누어야 합니다.
컴퓨터에 GPU 카드가 여러 개 있다면 각 GPU를 하나의 프로세스에 할당하는 것이 간단한 해결책입니다. CUDA_VISIBLE_DEVICES 환경 변수를 설정해 각 프로세스가 해당되는 GPU 카드만 보게할 수 있습니다. CUDA_DEVICE_ORDER = PCI_BUS_ID로 설정해 각 ID가 항상 동일한 GPU 카드를 참조하도록 합니다. 가령, GPU 카드가 4개 있다면 GPU를 각각 2개씩 할당한 프로그램 2개를 실행할 수 있습니다.
$ CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0,1 python3 program_1.py
$ CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=3,2 python3 program_2.py
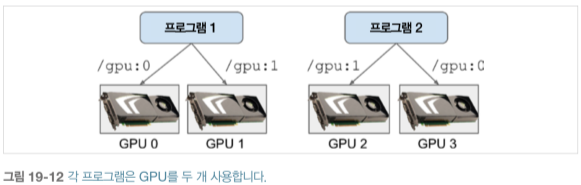
프로그램 1은 GPU 카드 0, 1만 봅니다. 각 이름은 /gpu:0, /gpu:1입니다. 프로그램 2는 GPU 카드 2, 3만 봅니다. 각 이름은 /gpu:1, /gpu:0입니다.(순서에 주의하세요)
텐서플로를 사용하기 전 os.environ["CUDA_DEVICE_ORDER"], os.environ["CUDA_VISIBLE_DEVICES"] 환경 변수를 파이썬에서 정의할 수도 있습니다.
또 다른 방법으로 텐서플로가 특정 양의 GPU RAM만 점유하도록 하는 것입니다. 반드시 텐서플로를 임포팅한 직후에 수행되어야 합니다. 아래 코드는 물리적인 GPU 장치에 대한 가상의 GPU 장치를 만들고 가상 GPU 메모리 한도를 2GiB(2,048MiB)로 설정한 것입니다.
for gpu in tf.config.experimental.list_physical_devices("GPU"):
tf.config.experimental.set_virtual_device_configuration(
gpu,
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=2048)])
4GiB RAM의 GPU가 4개 있다고 가정하면 프로그램 2개에서 4개를 모두 2GiB씩만 사용해 동시에 실행할 수 있습니다.

$ nvidia-smi위 명령어를 실행하면 각 프로세스가 카드마다 2GiB RAM만 사용하는 것을 볼 수 있습니다.
또 다른 방법은 텐서플로가 필요할 때만 메모리를 점유하게 만드는 것입니다. 이 또한 텐서플로를 임포트한 직후 설정해야 합니다.
for gpu in tf.config.experimental.list_physical_devices("GPU"):
tf.config.experimental.set_memory_growth(gpu, True)
이는 TF_FORCE_GPU_ALLOW_GROWTH 환경 변수를 true로 설정하는 것과 같습니다. 이렇게 하면 텐서플로는 프로그램이 종료되기 전까지 한 번 점유한 메모리를 다시 해제하지 않습니다. 이는 메모리 단편화를 막기 위해서입니다. 이렇게 할 경우 다른 프로그램 메모리 사용량이 급격히 올라가면 프로그램이 중지될 수 있어서 제품에 적용하지는 않습니다. 하지만, 이 방법이 유용할 때는 한 머신에서 텐서플로를 사용하는 jupytor notebook을 여러 개 실행할 때입니다. Colab Runtime에서 TF_FORCE_GPU_ALLOW_GROWTH 환경 변수가 true로 설정된 이유입니다.
마지막으로 GPU를 두 개 이상의 가상 GPU로 나누는 방법입니다. 분산 알고리즘을 테스트하는 경우입니다.? 다음 코드는 첫 번째 GPU를 2GiB RAM의 가상 GPU 2개로 나눕니다.
physical_gpus = tf.config.experimental.list_physical_devices("GPU")
tf.config.experimental.set_virtual_device_configuration(
physical_gpus[0],
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=2048),
tf.config.experimental.VirtualDeviceConfiguration(memory_limit=2048)])
이 두 가상 장치의 이름은 /gpu:0, /gpu:1입니다. 실제로 독립적인 GPU처럼 연산, 변수를 각각 할당할 수 있습니다.
디바이스에 연산과 변수 할당하기
텐서플로 백서('TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems')에는 모든 장치에 연산을 자동으로 분산하는 동적 배치자(dynamic placer) 알고리즘이 소개되어 있습니다. 실전에서 이 알고리즘은 사용자가 지정한 배치(placement) 규칙 몇 개보다 비효율적이라서 텐서플로 팀은 동적 배치자를 삭제했습니다.
tf.keras, tf.data는 일반적으로 연산과 변수를 잘 배치합니다. 가령, GPU에 연산량이 높은 걸 배치하고 CPU에는 데이터 전처리를 배치합니다. 하지만 상세하게 제어하고 싶다면 수동으로 각 장치에 연산과 변수를 배치할 수도 있습니다.
- 일반적으로 데이터 전처리는 CPU에, 신경망 연산은 GPU에 배치합니다.
- GPU는 보통 통신 대역폭에 제약이 많습니다. 따라서 GPU 입출력에 불필요한 데이터 전송을 피하는게 중요합니다.
- CPU RAM을 머신에 추가하는 것은 간단하고 저렴해서 일반적으로 넉넉하게 사용합니다. 반면 GPU RAM은 GPU에 고정되어 있습니다. 따라서 비싸고 제한된 자원이기에 다음 훈련 스텝 몇 번에서 어떤 변수가 필요하지 않다면 CPU에 배치해야 합니다.(가령, 데이터셋은 일반적으로 CPU에 놓입니다.)
기본적으로 GPU 커널이 없는 경우를 제외하고 모든 변수와 연산은 이름이 첫 번째 GPU(/gpu:0)에 배치될 것입니다. GPU 커널이 없는 변수, 연산은 CPU(/cpu:0)에 배치됩니다. 텐서나 변수의 device 속성에서 배치된 장치를 알 수 있습니다.
a = tf.Variable(42.0)
a.device
>> '/job:localhost/replica:0/task:0/device:GPU:0'
b = tf.Variable(42)
b.device
>> '/job:localhost/replica:0/task:0/device:CPU:0'
정수 변수에 대한 GPU 커널이 없기 때문에 b는 텐서플로가 CPU에 배치했습니다.
Tip
커널은 특정 데이터 타입과 장치를 위한 변수나 연산의 구현입니다. 가령 float32 tf.matmul() 연산의 GPU 커널이 있지만 int32 tf.matmul()의 GPU 커널은 없습니다.(CPU 커널만 있습니다.)
tf.debugging.set_log_device_placement(True)를 사용해 모든 장치의 배치 과정을 로깅할 수 있습니다.
연산을 기본 장치 대신 다른 장치에 배치하려면 tf.device() 컨텍스트(context)를 사용합니다.
with tf.device("/cpu:0"):
c = tf.Variable(42.0)
c.device
>> '/job:localhost/replica:0/task:0/device:CPU:0'
NOTE_
CPU 코어를 여러개 가진 머신도 CPU는 항상 하나의 장치(/cpu:0)처럼 취급됩니다. CPU에 배치된 연산이 멀티스레드 커널을 가지고 있다면 여러 코어에서 병렬로 실행될 수 있습니다.
연산·변수를 해당 커널이 없는 장치에 배치하면 예외가 발생합니다. 예외를 발생하는 대신 CPU로 배치되도록 할 수 있습니다. 프로그램이 CPU만 있는 머신과 GPU 머신 둘 다에서 실행될 수 있다면, CPU만 있는 머신에서 tf.device("/gpu:0*")를 무시해야합니다.? 이렇게 하려면 텐서플로가 임포트된 직후 tf.config.set_soft_device_placement(True)를 호출합니다. 만약 배치 요청에 실패하면 텐서플로가 기본 배치 규칙(즉, GPU 커널이 있으면 GPU 0, 그렇지 않으면 CPU 0)을 따릅니다.
구체적으로 텐서플로가 연산을 어떻게 여러 장치에서 실행할까요?
다중 장치에서 병렬 실행
12장에서 설명하였듯 TF 함수의 장점은 병렬화입니다. 텐서플로는 TF 함수를 실행할 때 그래프를 분석하여 평가할 연산의 목록을 찾고, 각 연산이 다른 연산에 얼마나 많이 의존하는지 카운트합니다.
그 다음 의존성이 전혀 없는 연산(source operation)을 연산이 할당된 장치의 평가 큐(evaluation queue)에 추가합니다.(아래 그림)

하나의 연산이 평가되면 그 연산에 의존하는 다른 모든 연산의 의존성 카운터(dependency counter)가 감소됩니다. 어떤 연산의 의존성 카운터가 0에 도달하면 장치의 평가 큐에 추가됩니다. 그리고 필요한 모든 노드가 평가되면 출력을 반환합니다.
CPU의 평가 큐에 있는 연산은 inter-op thread pool로 보내집니다. CPU가 여러 코어를 가지고 있으면 각 코어가 병렬로 평가합니다. 만약 멀티스레드 CPU 커널을 가지고 있으면 작업을 여러 부분 연산으로 쪼개서 다른 평가 큐에 배치하고 intra-op thread pool로 보내집니다.
GPU의 평가 큐에 있는 연산은 그냥 순서대로 평가됩니다. 만은 연산은 텐서플로가 사용하는 CUDA, cuDNN 같은 라이브러리로 구현된 멀티스레드 GPU 커널을 가지고 있습니다. 이런 구현은 자체 스레드 풀을 가지며 가능한 많은 GPU 스레드를 활용합니다. 각 연산이 대부분의 GPU 스레드를 사용해서 inter-op 스레드 풀이 필요 없습니다.
[19-14] 그림에서 A, B, C는 소스 연산입니다. A, B는 CPU에 배치되고 C는 GPU에 배치됩니다. A, B는 CPU 평가 큐 → inter-op thread pool로 보내져 즉시 병렬로 평가됩니다. A는 연산을 세 부분으로 나누는 멀티스레드 커널을 가지고 있어서 intra-op 스레드 풀에 의해 병렬로 평가됩니다. C는 GPU 0의 평가 큐 → GPU 커널 자체의 intra-op thread pool로 보내져 다수의 GPU 스레드에서 병렬로 평가합니다. C가 먼저 완료된다면 D와 E의 의존성 카운터가 0이 되어 GPU 0의 평가 큐에 추가되고 순차적으로 실행됩니다. 이런 식으로 모든 연산이 끝나면 텐서플로는 요청받은 출력을 반환합니다.
TF 함수는 변수 같이 상태가 있는 리소스를 수정할 때 코드 사이에 명시적인 의존성이 없더라도 코드의 순서와 맞도록 실행시킵니다. 가령, v.assign_add(1) 다음에 v.assign(v*2) 코드를 포함한다면 텐서플로는 이 순서에 맞추어 연산을 실행합니다.
Tip
tf.config.threading.set_inter_op_parallelism_threads()를 호출해 inter-op 스레드 풀에 있는 스레드 개수를 바꿀 수 있습니다. intra-op 스래드 개수고 set_inter → set_intra로 바꾸면 스래드 개수를 바꿀 수 있습니다. 이 함수는 텐서플로가 모든 CPU 코어를 사용하지 못하게 하거나 하나의 스레드만 사용하도록 할 때 유용합니다.
TF 함수의 병렬 연산 등을 활용한 몇 가지 사례를 소개합니다.
- 여러 모델을 각기 다른 GPU에서 병렬로 훈련할 수 있습니다. 각 훈련 스크립트에 CUDA_DEVICE_ORDER과 CUDA_VISIBLE_DEVICES를 지정해 각 스크립트가 1개의 GPU만 보도록 설정해 벼렬로 실행할 수 있습니다. 다른 하이퍼 파라미터로 여러 모델을 병렬로 훈련해서 하이퍼파라미터 튜닝 시 도움이 됩니다.
- 하나의 GPU에서 모델을 훈련하면서 CPU에서 병렬로 전처리를 수행할 수 있습니다. 데이터셋의 prefetch() 메서드를 사용해 다음 batch 몇 개를 미리 준비해 GPU에서 필요할 때 바로 쓸 수 있습니다. tf.data.experimental.prefetch_to_device()를 데이터를 프리페치하고 이를 선택한 장치로 보낼 수 있습니다.
- 모델이 이미지 2개를 입력 받고 다른 2개의 CNN을 이미지 각각에 사용해 처리해서 그 출력을 합친다면 각 CNN을 다른 GPU에 배치해 훨씬 빠르게 실행할 수 있습니다.
- 효율적인 앙상블 모델을 만들 수 있습니다. GPU마다 훈련된 다른 모델을 배치하면 훨씬 빠르게 예측을 모아서 앙상블의 최종 예측을 만들 수 있습니다.
여러 GPU에서 하나의 모델을 훈련하려면 어떻게 해야 할까요?
다중 장치에서 모델 훈련하기
여러 장치에서 하나의 모델을 훈련하는 방법에는 두 가지가 있습니다. 모델을 여러 장치에 분할하는 모델 병렬화(model parallelism)와 모델을 각 장치에 복사하고 복사본(replica)을 데이터 일부분에서 훈련하는 데이터 병렬화(data parallelism)가 있습니다.
모델 병렬화
신경망 하나를 여러 부분으로 나누어 각 부분을 장치 여러 개에서 실행할 수 있습니다. 완전 연결 신경망의 경우 수직으로 모델을 분리해각 장치에 배치해도 장치 간 통신이 매우 많이 발생해서(파선 화살표) 장치 간 통신이 매우 느리므로(특히 다른 머신 사이에서 일어난다면) 병렬 계산의 장점을 모두 상쇄합니다.

합성곱 신경망 같은 어떤 신경망 구조는 아래쪽 층에 부분적으로 연결된 층을 가집니다. 그래서 여러 장치에 효율적으로 모델을 분산하기 쉽습니다.

심층 순환 신경망은 여러 GPU에 조금 더 효율적으로 나눌 수 있습니다. 이 네트워크를 수평으로 분할해서 각 층을 다른 장치에 배치하고 batch로 처리할 입력 시퀀스를 이 네트워크에 주입하면 첫 번째 step에서는 (시퀀스의 첫 번째 값을 처리하기 위해) 하나의 장치만 사용되고 두 번재 step에서는 두 개가 사용됩니다. (두 번째 층은 첫 번째 값에 대한 첫 번째 층의 출력을 처리하고 그 동안 첫 번째 층은 두 번째 값을 처리합니다.)

이런 식으로 출력층까지 전파될 때는 모든 장치가 동시에 작동합니다. 여전히 장치 사이에 통신이 많지만 각 셀이 상당히 복잡해서 이론적으로는 많은 셀을 병렬로 실행하는 이점이 더 큽니다. 하지만 실제로는 LSTM 층을 쌓아 하나의 GPU에서 실행하는 것이 훨씬 빠릅니다.
간단히 요약하면 모델 병렬화는 일부 신경망의 실행과 훈련 속도를 높일 수 있지만, 같은 머신의 장치끼리 통신하게 하는 등 특별한 조정과 튜닝이 필요합니다. 모델 병렬화에 관심이 있다면 메시 텐서플로(https://github.com/tensorflow/mesh)를 확인하세요.
데이터 병렬화
신경망의 훈련을 병렬화하는 또 다른 방법은 각 장치에 모델을 복제해서 각각 다른 미니 배치를 사용해 모든 모델이 동시에 훈련 스텝을 실행하는 것입니다. 복제 모델에서 계산된 그레디언트를 평균하고 그 결과를 사용해 모델 파라미터를 업데이트합니다. 이를 데이터 병렬화(data parallelism)라고 합니다.
미러드 전략을 사용한 데이터 병렬화

가장 간단한 방법은 모든 GPU의 모델 복사본의 파라미터를 동일한 상태로 유지시켜주는 것입니다. 업데이트 시 모든 GPU에서 얻은 그레디언트의 평균을 계산해 모든 GPU에 배포합니다. 그레디언트의 평균은 AllReduce 알고리즘을 사용해 처리할 수 있습니다. AllReduce는 여러 개의 노드가 협력해 (평균, 합, 최댓값을 계산하는 것과 같은) reduce 연산을 효율적으로 실행하고 모든 노드가 동일한 최종 결과를 얻게 하는 알고리즘입니다.
중앙 집중적인 파라미터를 사용한 데이터 병렬화
데이터 병렬화의 또 다른 방식은 worker 밖에 모델 파라미터를 저장하는 것입니다. 계산을 수행하는 GPU를 worker라고 부릅니다. 분산 환경에서는 파라미터를 하나 이상의 CPU만 존재하는 서버에 저장합니다. 이 서버는 파라미터를 보관 · 업데이트합니다.

미러드 전략은 모든 GPU에 동기화된 가중치 업데이트를 적용합니다. 반면, 중앙 집중적인 방식은 동기·비동기 업데이트를 모두 사용할 수 있습니다.
동기 업데이트
동기 업데이트(synchronous update)는 그레디언트 수집기가 모든 그레디언트가 준비될 때까지 기다린 후 평균을 계산하고 옵티마이저에게 전달합니다. 때문에 한 장치가 다른 장치보다 느리면 모든 장치가 느린 장치를 매 스텝마다 기다려야합니다. 또한 모델 파라미터가 모든 장치에 복사되어서 파라미터 서버의 대역폭을 포화시킬 수 있습니다.
Tip
매 스텝 대기 시간을 줄이기 위해 느린 일부 복제 모델에서 오는 그레디언트를 무시할 수 있습니다. 예를 들어 복제 모델이 20개 있을 때 가장 빠른 모델 18개의 응답만 취합합니다. 파라미터가 업데이트되자마자 18개 모델은 느린 모델 2개를 기다릴 필요 없이 즉시 작동할 수 있습니다. 이런 설정을 18개 복제 모델과 2개의 여분의 복제 모델(spare replica)이라 합니다.
이는 일부 복제 모델이 아무것도 하지 않는 것처럼 보일 수 있습니다. 만약, 모든 모델의 장치가 다른 것보다 느리지 않다면 누락되는 모델은 매 스탭마다 달라집니다. 만약 한 서버가 다운되어도 훈련은 이상 없이 계속 진행되는 장점도 있습니다.
비동기 업데이트
비동기 업데이트(asynchronous updates)에서는 복제 모델 각각이 그레디언트 계산을 끝내면 즉시 모델 파라미터를 업데이트하빈다. 여기에서는 수집·평균 단계가 삭제됩니다. 여전히 매 단계마다 파라미터는 모든 장치에 복사됩니다. 하지만, 복제 모델 마다 각기 다른 시간에 모든 장치에 복사시키므로 대역폭이 포화되는 위험은 줄어들고, 다른 복제 모델을 대기하지 않기 때문에 분당 더 많은 훈련 스텝을 실행할 수 있습니다.

비동기 업데이트의 단점은 실전에서 이 방식이 전혀 효과가 없다는 것입니다. 위 그림 처럼 계산된 그레디언트가 정확한 방향을 가리킬 것이라는 보장이 없습니다. 그레디언트가 심하게 오래될 때 이를 낡은 그레디언트(stale gradient)라고합니다. 이는 수렴을 느리게 만들고 잡음을 발생시키거나 모델을 발산시키기도 합니다.
stale gradient 현상을 줄이는 방법들이 있습니다.
- 학습률 감소
- stale gradient를 drop하거나 크기↓
- 미니배치 크기 조절
- 하나의 복제 모델만 사용해 처음 몇 번의 에포크를 시작합니다. 이를 준비 단계(warmup phase)라고 합니다. 일반적으로 그레디언트가 크거나 파라미터가 비용 함수 계곡 부분에 안착하지 못했을 때 다른 복제모델이 파라미터를 매우 다른 방향으로 이동할 수 있어 stale gradient가 훈련 초기에 더 큰 문제를 일으키는 경향이 있습니다.
일반적으로 spare replica가 있는 동기 업데이트가 데이터 병렬화를 빠르게 수렴시키고 더 좋은 모델을 만든다는 논문이 있습니다.(Revisiting Distributed Synchronous SGD)
대역폭 포화
중앙 집중적인 파라미터를 사용하는 데이터 병렬화는 매 훈련 스텝이 시작될 때 파라미터 서버에서 모든 복제 모델로 모델 파라미터를 전송해야 합니다. 그리고 훈련 스텝이 끝날 때 그레디언트를 모델에서 서버로 전달합니다. 비슷하게 미러드 전략에서도 각 GPU에서 계산한 그레디언트가 다른 GPU와 공유되어야 합니다.
이는 여분의 GPU를 추가하더라고 GPU RAM의 입력과 출력으로 데이터를 옮기는 데 드는 시간이 계산 부하를 분할하는 것보다 더 커서, 성능을 전혀 향상하지 못한다는 것을 의미합니다. 이런 점에서 GPU를 추가할 수록 대역폭을 더 포화시키고 훈련을 느리게 만듭니다.
Tip
모델의 규모가 작고 매우 큰 훈련 세트에서는 메모리 대역폭이 크고 성능이 높은 GPU 하나가 장착된 단일 머신에서 모델을 훈련시키는 것이 종종 더 낫습니다.
대역폭 포화는 전송할 파라미터, 그레디언트가 많아서 대규모 밀집 모델에서는 더 큰 문제가 됩니다. 작거나 크지만 희소한 모델에서는 대부분 그레디언트가 0이므로 효율적으로 통신할 수 있습니다. 밀집 모델에서 GPU 수십 개, 희소 모델에서 GPU 수백 개를 넘어서면 대역폭 포화가 되고 성능이 감소하기 시작합니다. 이 문제를 해결하기 위해 중앙 파라미터 서버 대신 peer-to-peer 구조, 손실 모델 압축, 복제 모델이 통신하는 시점 최적화 등 연구가 많이 진행되고 있습니다. 몇 년 안에 신경망 병렬화에 많은 진전이 있을 것입니다.
그 동안에는 저렴한 GPU를 많이 쓰는 것보다 강력한 GPU를 몇 개 사용하는 것이 좋습니다. 또한 GPU를 네트워크 연결이 잘 되는 서버 몇 대에 모아야합니다. 실수 정밀도를 tf.float32 → tf.float16으로 감소시킬 수도 있습니다. 이는 수렴 속도, 모델 성능에 크게 연향을 끼치지 않고 전송하는 데이터 양을 절반으로 줄일 수 있습니다. 마지막으로 중앙 집중적인 서버를 사용할 때 파라미터를 서버 여러 대에 나누면 네트워크 부하를 줄이고 대역폭 포화의 위험을 제한할 수 있습니다.
분산 전략 API를 사용한 대규모 훈련
같은 머신에 GPU를 여러 개 가진 서버 여러 대에서 모델을 훈련할 수 있습니다. 이것으로도 충분하지 않다면 모델 병렬화를 사용해볼 수 있습니다.
텐서플로는 간단한 분산 전략 API를 제공합니다. 미러드 전략으로 데이터 병렬화를 사용해 가능한 모든 GPU에서 케라스 모델을 훈련하려면 MirroredStrategy 객체를 만들고 scope() 메서드를 호출하여 분산 컨텍스트를 얻습니다. 이 컨텍스트로 모델 생성, 컴파일 과정을 감싼 후 보통과 같이 모델의 fit() 메서드를 호출합니다.
distribution = tf.distribute.MirroredStrategy()
with distribution.scope():
mirrored_model = keras.models.Sequential([..])
mirrored_model.compile([..])
batch_size = 100 # 복제 모델 개수로 나누어 떨어져야 합니다.
history = mirrored_model.fit(X_train, y_train, epochs=10)
내부적으로 tf.keras는 분산을 자동으로 인식합니다. MirroredStrategy 컨텍스트 안에서 모든 변수, 연산이 가능한 모든 GPU 장치에 복제되어야 하는 것을 알고 있습니다. fit() 메서드는 자동으로 훈련 배치를 모든 복제 모델에 나눕니다.
모델의 훈련이 끝나고 predict() 메서드를 호출하면 모든 복제 모델에 batch를 나누어 예측합니다. 예측에서도 배치 크기는 복제 모델의 개수로 나누어 떨어져야 합니다. 모델에 save() 메서드를 호출하면 일반적인 모델로 저장됩니다. 즉, 모델을 다시 로드하면 하나의 장치(GPU 0)를 가진 일반 모델처럼 실행됩니다.
모든 장치에서 실행하고 싶다면 분산 컨텍스트 안에서 keras.models.load_model()을 호출해야 합니다.
with distribution.scope():
mirrored_model = keras.models.load_model("my_mnist_model.h5")
가능한 GPU 중 일부만 사용하고 싶다면 MirroredStrategy 생성자에 장치 리스트를 전달할 수 있습니다.
distribution = tf.distribute.MirroredStrategy(["/gpu:0", "/gpu:1"])
MirroredStrategy 클래스는 평균을 계산하는 올리듀스 연산을 위해 NCCL(NVIDIA Collective Communications Library)을 사용합니다. 기본 NCCL 옵션은 tf.distribute.NcclAllReduce 클래스를 기반으로 하지만, tf.distribute.HierarchicalCopyAllReduce 클래스의 인스턴스나 tf.distribute.ReductionToOneDevice 클래스의 인스턴스에 cross_device_ops 매개변수를 설정하여 바꿀 수 있습니다. tf.distribute.NcclAllReduce 클래스는 일반적으로 빠르지만, GPU 개수·종류에 의존성이 있습니다. 올리듀스 알고리즘에 대한 더 자세한 내용은 (https://homl.info/uenopost), (https://homl.info/ncclalgo)를 참고하세요.
중앙 집중적인 파라미터로 데이터 병렬화를 사용하려면 MirroredStrategy를 CentralStorageStrategy로 바꾸면 됩니다.
distribution = tf.distribute.experimental.CentralStorageStrategy()
compute_devices 매개변수에 워커로 사용할 장치 목록을 지정할 수 있습니다. 기본적으로 가능한 모든 GPU를 사용합니다. 또는 선택적으로 parameter_device 매개변수에 파라미터를 저장할 장치를 지정할 수 있습니다.
이제 텐서플로 서버 클러스터에서 모델을 어떻게 훈련하는지 알아보겠습니다.
텐서플로 클러스터에서 모델 훈련하기
텐서플로 클러스터(Tensorflow cluster)는 다른 머신에서 동시에 실행되는 텐서플로 프로세스 그룹입니다. 클러스터는 신경망 훈련·실행의 작업을 완료하기 위해 서로 통신합니다. 클러스터에 있는 개별 TF 프로세스를 task 또는 TF server라고 부릅니다.
task는 ip 주소, port, type(role 또는 job이라고도 부름)을 가집니다. type은 'worker', 'chief', 'ps'(파라미터 서버), 'evaluator' 중에 하나입니다.
- 각 worker는 GPU 한 개 이상을 가진 머신에서 계산을 수행합니다.
- chief도 하나의 worker로 계산을 수행하나 텐서보드 로그·체크포인트 저장 같은 추가적인 일을 처리합니다. 클러스터에는 하나의 chief가 있고, chief를 지정하지 않으면 첫 번째 worker가 chief가 됩니다.
- parameter server는 변숫값만 저장하고 일반적으로 CPU만 있는 머신을 사용합니다. 이 task의 type은 ParameterServerStrategy만 사용합니다.
- evaluator는 평가를 처리합니다.
cluster specification(클러스터 명세)는 task의 ip, port, type을 정의하는 것을 말합니다. 아래 코드는 task 3개(worker2개, parameter server 1개)를 가진 cluster를 정의합니다. 클러스터 명세는 key가 1개의 job이고 value는 ip:port의 리스트입니다.
cluster_spec ={
'worker': [
'machine-a.example.com:2222', # /job:worker/task:0
'machine-b.example.com:2222' # /job:worker/task:1
],
'ps': ['machine-a.example.com:2221'] # /job:ps/task:0
}
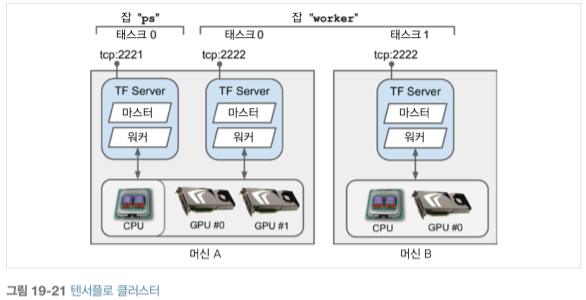
일반적으로 머신마다 task 1개이지만, 필요하다면 머신 A처럼 여러 개의 task를 설정할 수 있습니다. 하나의 GPU를 나누어 쓰려면 앞에서 언급한 것처럼 적절히 RAM을 분할해야 합니다.
CAUTION_
기본적으로 클러스터에 있는 task는 다른 모든 task와 통신할 수 있습니다. 따라서 머신들의 포트 간에 통신이 가능하도록 방화벽을 설정해야합니다. (모든 머신이 같은 포트를 사용하면 설정하기 쉽습니다.)
task를 시작할 때, 클러스터 명세, 이 태스크의 type, index(예를 들면, worker 0)가 무엇인지 알려주어야합니다. 이는 TF_CONFIG 환경 변수를 설정하면 됩니다. cluster 키 아래 클러스터 명세와 task 키 아래 현재 테스크 type, index를 담은 JSON으로 인코딩하여 입력합니다.
import os
import json
os.environ['TF_CONFIG'] = json.dumps({
'cluster': cluster_spec,
'task': {'type': 'worker', 'index': 0}
})
방금 정의한 cluster를 사용하고 시작하려는 task가 첫 번째 worker라는 것을 지정합니다.
Tip
일반적으로 파이썬 밖에서 TF_CONFIG 환경 변수를 정의하는 것이 선호됩니다. 따라서 코드에 현재 태스크의 타입과 인덱스를 포함할 필요가 없습니다. 이렇게 하면 동일한 코드를 모든 워커에서 사용할 수 있습니다.
이제 클러스터에서 모델을 훈련하겠습니다. 미러드 전략을 시작해보겠습니다. 먼저 task에 맞게 TF_CONFIG 환경 변수를 적절히 설정합니다. 파라미터 서버가 없고 (클러스터 명세에서 'ps'를 삭제합니다.) 보통 하나의 머신에 하나의 워커를 설정합니다. 각 task에 대해 다른 task index를 설정해야한다는 것을 주의하세요. 마지막으로 각 워커에서 다음 훈련 코드를 실행합니다.
distribution = tf.distribute.experimental.MultiWorkerMirroredStrategy()
with distribution.scope():
mirrored_model = keras.models.Sequential([...])
mirrored_model.compile([...])
batch_size = 100 # 복제 모델 개수로 나누어 떨어져야 합니다.
history = mirrored_model.fit(X_train, y_train, epochs=10)
첫 번째 워커에서 이 스크립트를 실행하면 올리듀스 스텝에서 멈추게 되고, 마지막 워커가 시작하자마자 훈련이 시작되고 정확히 같은 속도로 진행되는 것을 볼 수 있습니다. (매 단계마다 동기화되기 때문에) ? why 마지막 워커가 올리듀스 스텝을 시작해야되는 것 아닌가?
이 분산 전략을 위해 2개의 올리듀스 중 1개를 사용할 수 있습니다. 네트워크 통신에 gRPC를 기반으로 하는 ring 올리듀스, NCCL 구현이 그것들입니다. 이 2개의 올리듀스는 워커 개수, GPU 개수·종류, 네트워크에 따라 최선의 알고리즘이 달라집니다.
어떤 알고리즘을 강제하고 싶다면 tf.distribute.experimental.CollectiveCommunication.RING 혹은 .NCCL를 전략 클래스의 생성자에 전달할 수 있습니다.
파라미터 서버를 사용한 비동기 데이터 병렬화는 전략을 ParameterServerStrategy로 바꾸고 하나 이상의 parameter server를 추가하고 각 태스크를 TF_CONFIG에 적절히 설정합니다. 워커가 비동기적으로 작동하지만 각 워커에 있는 복제 모델들은 동기적으로 작동할 것입니다.
마지막으로 GCP의 TPU를 사용할 수 있다면 다음과 같이 TPUStrategy를 만들 수 있습니다. 사용법은 다른 strategy와 동일합니다.
resolver = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.tpu.experimental.initializer_tpu_system(resolver)
tpu_strategy = tf.distribute.experimental.TPUStrategy(resolver)
Tip
연구원이라면 TPU를 무료로 쓸 수 있습니다. https://tensorflow.org/tfrc를 참고하세요.
이제 GPU 여러 개와 서버 여러 대에서 모델을 훈련할 수 있습니다. 대규모 모델을 훈련하려면 많은 서버와 GPU가 필요합니다. GCP를 사용하면 덜 복잡하고 저렴한 비용으로 대규모 모델을 훈련할 수 있습니다.
구글 클라우드 AI 플랫폼에서 대규모 훈련 실행하기
구글 AI 플랫폼은 필요한 GPU VM을 준비하고 설정합니다. job(작업)을 시작하려면 구글 클라우드 SDK에 포함된 gcloud 명령줄 도구를 사용해야 합니다. 자신의 PC에 이 SDK를 설치하거나 GCP의 구글 클라우드 셸을 사용할 수 있습니다. 클라우드 셸은 SDK가 이미 설치된 사용자에 맞게 설정된 무료 리눅스 VM(데비안)에서 실행됩니다.

위 그림 처럼 클라우드 셸은 GCP 화면 어디에서든지 사용할 수 있습니다.
PC에 SDK를 설치하는 것이 좋다면 설치한 후 gcloud init 명령을 실행해 초기화해야 합니다. 이를 통해 GCP에 로그인하고 GCP 자원에 접근할 수 있는 권한을 받아야 합니다. 그 다음 (프로젝트가 1개 이상이면) 사용하려는 GCP 프로젝트와 작업을 실행한 리전을 선택합니다. gcloud 명령을 사용해 앞서 했던 것을 포함해 모든 GCP 기능을 조작할 수 있습니다. 매번 웹 인터페이스를 사용할 필요가 없습니다. 스크립트를 만들어 VM을 시작·종료·모델 배포 등 어떤 GCP 기능도 수행할 수 있습니다.
훈련 작업을 실행하기 전 분산 설정(ex, ParameterServerStrategy를 사용해서)으로 앞서 만들었던 것과 동일한 훈련 코드를 작성해야 합니다. AI 플랫폼이 TF_CONFIG를 대신 설정해줄 것입니다. 코드가 작성되면 이 스크립트를 다음과 같은 명령으로 TF 클러스터에 배포하고 실행할 수 있을 것입니다.
$ gcloud ai-platform jobs submit training my_job_20190531_164700 \
--region asia-southeast1\
--scale-tier PREMIUM_1\
--runtime-version 2.0\
--python-version 3.5\
--package-path /my_project/src/trainer\
--module-name trainer.task\
--staging-bucket gs://my-staging-bucket\
--job-dir gs://my-mnist-model-bucket/trained_model \
--
--my-extra-argument1 foo --my-extra-argument2 bar
- asia-southeast1 리전에 my_job_20190531_164700이란 이름의 훈련 작업을 시작합니다.
- PREMIUM_1 확장 등급(scale tier)을 사용합니다. 이는 chief를 포함해 worker 20개, ps 11개를 사용할 수 있습니다. 다른 확장 등급도 확인해보세요.(https://homl.info/scaletiers)
- 이런 VM은 모두 AI 플랫폼 2.0 런타임과 파이썬 3.5를 기반으로 합니다.
- 훈련 코드는 /my_project/src/trainer 디렉터리에 있고 자동으로 pip 패키지로 만들어 GCS의 gs://my-staging-bucket 위치에 업로드합니다.
- 그 다음 AI 플랫폼이 몇 개의 VM을 만들어 패키지를 배포한 후 trainer.task 모듈을 실행할 것입니다.
- 마지막으로 --job-dir 매개변수와 추가 매개변수( 추가 -- 구분자 이후에 있는 매개변수)는 훈련 프로그램으로 전달됩니다.
- chief task는 매개변수 --job-dir을 사용해 GCS에 저장된 최종 모델의 위치를 찾습니다. 이 예에서는 gs://my-mnist-model-bucket/trained_model입니다.
GCP 콘솔에서 메뉴 → 인공지능 섹션 → AI Platform → 작업에서 실행중인 작업을 볼 수 있습니다. CPU, GPU, RAM 사용량 그래프를 볼 수 있고, View Logs를 클릭하면 스택 드라이버를 사용해 자세한 로그를 확인할 수 있습니다.
NOTE_
훈련 데이터를 GCS에 저장한다면 이를 참조하는 tf.data.TextLineDataset이나 tf.data.TFRecoedDataset을 만들 수 있습니다. 파일 이름처럼 GCS 경로를 사용하면 됩니다.(예를 들어, gs://my-data-bucket/my_data_001.csv) 이 데이터 셋은 파일에 접근하기 위해 tf.io.gfile 패키지를 사용합니다. 이 패키지는 로컬 파일과 GCS 파일을 모두 지원합니다. (사용하는 서비스 계정에 GCS 권한이 있는지 확인하세요.)?
몇 개의 하이퍼파라미터 값을 조사하려면 작업을 여러 개 실행하고 task의 추가 매개변수를 사용해 하이퍼파라미터값을 지정할 수 있습니다. 많은 하이퍼파라미터를 효율적으로 탐색하려면 AI 플랫폼의 하이퍼파라미터 튜닝 서비스를 사용하는 것이 좋습니다.
AI 플랫폼에서 블랙 박스 하이퍼파라미터 튜닝
AI 플랫폼은 Google Vizier라는 강력한 Bayesian 최적화 하이퍼파라미터 튜닝 서비스를 제공합니다. 이를 사용하려면 작업을 만들 때 YAML 설정 파일을 전달해야합니다.(--config tuning.yaml) 예를 들면 이 파일은 다음과 같습니다.
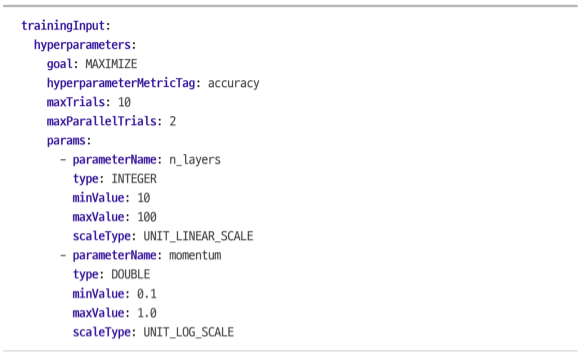
이 파일은 AI 플랫폼에게 accuracy라는 측정 지표를 최대화하라고 요청합니다. 이 작업은 최대 10번 시도합니다. 각 시도에서 훈련 코드를 실행해 처음부터 모델을 훈련합니다. 동시에 실행하는 최대 시도 횟수는 2입니다.
2개의 하이퍼파라미터를 튜닝합니다. n_layers와 momentum입니다. 각 하이퍼 파라미터의 범위를 지정해줍니다. (10~100) & (0.1~1.0) scaleType은 하이퍼파라미터에 대한 사전 정보를 전달합니다. UNIT_LINEAR_SCALE은 평등한 우선순위를 가집니다. 이는 사전 정보가 없다는 것을 의미합니다. UNIT_LOG_SCALE은 최적값이 최댓값 근처에 있다는 정보를 줍니다. 다른 옵션으로 UNIT_REVERSE_LOG_SCALE이 있는데, 이는 최적값이 최솟값 가까이 있다는 것을 의미합니다.
n_layers와 momentum 매개변수는 명령줄 매개변수로 훈련 코드에 전달될 것입니다. 당연히 해당 코드는 이 매개변수를 사용할 것입니다. AI 플랫폼은 accuracy 측정 지표(이름이 무엇이든 hyperparameterMetricTag로 지정된 측정 지표)의 결과를 담은 (10장에서 소개한) 이벤트 파일을 위해 (--job-dir로 지정된) 출력 디렉터리를 감시하여 이 값을 읽습니다. 따라서 훈련 코드가 (모니터링을 위해 필요한) TensorBoard() 콜백을 사용해야 합니다. 이제 실행하면 됩니다!?
작업이 완료되면 각 시도에서 사용한 모든 하이퍼파라미터 값과 정확도 결과가 작업의 출력으로 포함됩니다. (AI Platform → 작업에서 볼 수 있습니다.)
NOTE_
AI 플랫폼의 작업은 대량의 데이터에서 모델을 효율적으로 실행하기 위해서 사용할 수 있습니다. 각 워커가 GCS에서 데이터의 일부분을 읽고 예측을 만들어 GCS에 저장할 수 있습니다.
이제 우리는 다양한 분산 전략을 사용해 대규모 훈련을 위한 도구와 지식을 갖췄고, 하이퍼파라미터 세부 튜닝을 위해 강력한 베이즈 최적화를 할 수도 있습니다.
출처: 핸즈온 머신러닝 2판
사진 출처: 핸즈온 머신러닝 2판
'핸즈온 머신러닝 2판' 카테고리의 다른 글
| 18장 강화 학습 (0) | 2022.02.07 |
|---|---|
| 이진 오토인코더를 이용한 해싱 (0) | 2022.02.06 |
| LSTM autoencoder (0) | 2022.02.04 |
| 17장 오토인코더와 GAN을 사용한 표현 학습과 생성적 학습 (2) | 2022.02.03 |
| 16장 RNN과 어텐션을 사용한 자연어 처리 (1) | 2022.01.26 |