RNN을 사용하면 time series, 고정된 길이가 아닌 sequence (문장, 문서, 오디오 ..)를 다룰 수 있습니다. 자동 번역, speech to text 같은 자연어 처리(NLP)에 매우 유용합니다.

RNN은 이전 타임 스텝의 출력을 다시 입력으로 받습니다.

$$y_{\left(t\right)}=\Phi \left(W_x^Tx_{\left(t\right)}+W_y^Ty_{\left(t-1\right)}+b\right)$$
$$Y_{\left(t\right)}=\Phi \left(\left[X_{\left(t\right)}\ \ \ Y_{\left(t-1\right)}\right]W+b\right)$$
$$W\ =\begin{bmatrix}W_x\\W_y\end{bmatrix}$$
Φ는 활성화 함수입니다. $Y_{\left(t\right)}$는 $X_{\left(t\right)}$와 $Y_{\left(t-1\right)}$에 대한 함수이고, $Y_{\left(t-1\right)}$은 $X_{\left(t-1\right)}$와 $Y_{\left(t-2\right)}$에 대한 함수이고 ... 따라서, $Y_{\left(t\right)}$는 t=0에서부터 모든 입력에 대한 함수가 됩니다.
메모리 셀
타임스텝 t에서 순환 뉴런의 출력은 이전 타임 스텝의 모든 입력에 대한 함수이므로, 일종의 메모리 형태라고 말할 수 있습니다. 타임 스텝에 걸쳐 어떤 상태를 보존하는 신경망의 구성 요소를 memory cell이라고 할 수 있습니다. cell은 완전 연결 신경망에서 층(layer)을 의미합니다.

$h_{\left(t\right)}=f\left(h_{\left(t-1\right)},\ x_{\left(t\right)}\right)$는 타임 스텝 t에서 셀의 상태를 의미합니다. 지금까지 이야기한 기본 셀의 경우 출력과 셀의 상태가 동일하지만, 위 그림처럼 출력과 상태는 다를 수 있습니다.
입력과 출력 시퀀스
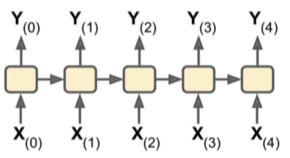
sequence-to-sequence network는 주식가격 같은 시계열 데이터를 예측하는데 쓰입니다. 각 출력은 입력값보다 하루 앞선 가격을 출력해야 합니다.

sequence-to-vector network는 영화 리뷰의 연속된 단어를 입력받아 감성 점수를 출력하는 데 쓰일 수 있습니다.

vector-to-sequence network는 이미지를 입력받아 이미지에 대한 캡션을 출력하는 데 쓰일 수 있습니다.

encoder(sequence-to-vector)와 decoder(vector-to-sequence)를 네트워크로 연결할 수도 있습니다. 한 언어의 문자을 받아 이를 다른 언어의 문장으로 번역하는 데 사용할 수 있습니다. sequence-to-sequence RNN보다 더 잘 작동하는데, 문장의 마지막 단어가 번역의 첫 번째 단어에 영향을 줄 수 있기 때문입니다. 이 구조는 전체 문장이 주입될 때까지 기다릴 필요가 있습니다.
RNN 훈련하기
RNN을 훈련하는 과정은 다음과 같습니다. 각 타임 스텝마다 정방향 패스(점선)로 비용 함수를 구하고, 비용 함수 $C\left(Y_{\left(0\right)},\ Y_{\left(1\right)},\ ...\ ,\ Y_{\left(T\right)}\right)$를 사용해 출력 시퀀스($Y_{\left(0\right)},\ Y_{\left(1\right)},\ ...\ ,\ Y_{\left(T\right)}$)가 평가됩니다. 역방향(실선)으로 비용 함수의 그레디어트가 전파됩니다. 이는 보통의 역전파와 비슷합니다. 각 타임 스텝마다 같은 매개변수 $W$, $b$를 사용하기 위해 일련의 타임 스텝을 진행한 후, 그레디언트가 전파됩니다.

위 그림에서는 $Y_{\left(2\right)},\ Y_{\left(3\right)},\ Y_{\left(4\right)}$를 사용하여 비용 함수가 계산됩니다. 따라서 그레디언트는 $Y_{\left(2\right)},\ Y_{\left(3\right)},\ Y_{\left(4\right)}$에만 전달됩니다.
시계열 예측하기
time series(시계열)은 univariate time series(단변량 시계열), multivariate time series(다변량 시계열)로 나눌 수 있습니다. 이는 타임 스텝마다 몇 개의 값을 갖느냐에 따라 구분한 것입니다.
시계열을 주로 사용하는 곳은 forecasting(예측), imputation(값 대체)에 사용합니다. 이는 미래의 값을 예측하는 것과, 과거 데이터에서 누락된 값을 예측하는 것입니다.
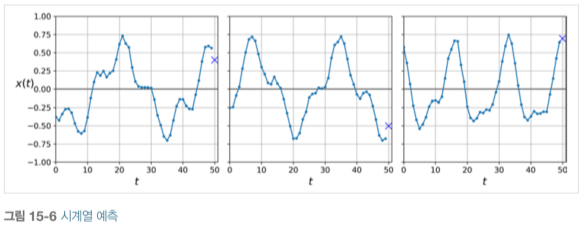
위 그림의 예제에서 각 시계열의 길이는 50이고, 목표는 'X'의 타임 스텝의 값을 예측하는 것입니다.
예제 시계열 데이터를 생성해보겠습니다.
def generate_time_series(batch_size, n_steps):
freq1, freq2, offsets1, offsets2 = np.random.rand(4, batch_size, 1)
# 0~1 사이의 shape (4, batch_size, 1)인 랜덤한 array 반환
time = np.linspace(0, 1, n_steps) # 0 ~ 1 사이를 50개로 균일하게 나눈 배열 반환
series = 0.5*np.sin((time-offsets1)*(freq1*10 + 10)) # 사인 곡선 1
series += 0.2*np.sin((time-offsets2)*(freq2*20 + 20)) # 사인 곡선2
series += 0.1*(np.random.rand(batch_size, n_steps) - 0.5) # 잡음 추가
return series[..., np.newaxis].astype(np.float32)
# (batch_size, n_steps) → (batch_size, n_steps, 1)로 형상 변경, newaxis는 차원을 늘려줌batch_size만큼 n_steps 길이의 단변량 시계열을 만듭니다. [batch_size, n_steps, 1]의 ndarray를 반환합니다.
n_steps = 50
series = generate_time_series(10000, n_steps +1)
X_train, y_train = series[:7000, :n_steps], series[:7000, -1]
# y_train은 마지막 정답 = series.iloc[0:7000, 50, 0] 51번째 스텝의 값
X_valid, y_valid = series[7000:9000, :n_steps], series[7000:9000, -1]
X_test, y_test = series[9000:, :n_steps], series[9000:, -1]데이터를 train : valid : test = 0.7 : 0.2 : 0.1 비율로 나누었습니다. 각 시계열 마다 하나의 값을 예측해야해서 타깃은 열벡터입니다. y_train는 [7000, 1] 크기입니다.
기준 성능
RNN을 사용하기 전 기준 성능 몇 개를 준비하는게 좋습니다. 그렇지 않으면, 실제 기본 모델보다 성능이 나쁜 데, 잘 동작한다고 생각할 수 있습니다. 몇 가지 방법을 소개합니다.
native forecasting (순진한 예측)은 각 시계열의 마지막 값을 그대로 예측하는 것입니다. 이 성능의 MSE는 0.020입니다. 가끔 이 성능을 뛰어넘는 것은 매우 어렵습니다.
y_pred = X_valid[:, -1]
np.mean(keras.losses.mean_squared_error(y_valid, y_pred))
# 0.020049721
완전 연결 네트워크를 기준 성능으로 사용할 수 있습니다. 이 네트워크는 입력마다 1차원 특성 배열을 기대하기 때문에 Flatten 층을 추가해야 합니다. MSE는 약 0.004를 얻을 수 있습니다.
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[50, 1]),
keras.layers.Dense(1)
])
model.compile(optimizer='Adam', loss='mse')
model.fit(X_train, y_train, validation_data=(X_valid, y_valid), epochs=20)
'''
Epoch 1/20
219/219 [==============================] - 1s 2ms/step - loss: 0.1388 - val_loss: 0.0625
...
Epoch 20/20
219/219 [==============================] - 0s 2ms/step - loss: 0.0037 - val_loss: 0.0036
'''
간단한 RNN 구현하기
RNN은 입력 시퀀스의 길이를 지정할 필요가 없습니다. 따라서 첫 번째 입력 차원을 None으로 지정했습니다. SimpleRNN 층은 default로 tanh를 activation func로 갖고 있습니다. 초기 상태$h_{(init)}$은 0으로 설정되어 있습니다. 이 층은 마지막 값인 $y_49$를 출력합니다.($y_0$이 $x_0$의 출력이라 했을 때)
기본적으로 케라스의 순환 층은 최종 출력만 반환합니다. 타임 스텝마다 출력을 반환하려면 return_sequences=True로 설정합니다.
model = keras.models.Sequential([
keras.layers.SimpleRNN(1, input_shape=[None, 1])
])
model.compile(optimizer='adam', loss='mse')
model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
'''
Epoch 1/20
219/219 [==============================] - 3s 10ms/step - loss: 0.2014 - val_loss: 0.1275
...
Epoch 20/20
219/219 [==============================] - 2s 9ms/step - loss: 0.0149 - val_loss: 0.0142
'''
MSE가 0.014로 간단한 선형 모델보다 성능이 떨어집니다. 선형 모델은 입력(타임 스텝)마다 하나의 파라미터를 갖고 있습니다. 편향도 가집니다. 따라서 51개의 파라미터를 갖지만, 기본 RNN의 순환 뉴런은 입력과 은닉 상태의 차원(기본 RNN에서는 층의 순환 뉴런 개수)마다 하나의 파라미터를 갖고 있고, 층마다 편향도 1개 가지고 있습니다. 따라서 기본 RNN에서는 3개의 파라미터를 사용한 것입니다.
트렌드와 계절성
weighted moving average(가중 이동 평균)과 autoregressive integrated moving average( ARIMA, 자동 회귀 누적 이동 평균) 같이 시계열을 예측하는 방법은 많습니다. 이런 방법들 중 일부는 trend(트렌드), seasonality(계절성)을 제거해야 합니다.
매달 10% 성장하는 웹사이트의 사용자 수를 조사한다면, 시계열에서 이런 트렌드를 제거해야하는데, 모델을 훈련하고 예측을 만들 때 최종 예측에 이 트렌드를 다시 더합니다.
선크림 판매량을 예측할 때 강한 계절성을 관찰할 수 있는데, 선크림은 여름에 더 많이 팔리기 때문에 이런 계절성을 삭제해야합니다. 매 타임 스텝값과 작년도 값의 차이를 계산해 사용합니다. 이런 기법을 differencing(차분)이라 부릅니다. 이 모델이 훈련되고 예측을 만든 후 계절 패턴을 최종 예측에 더합니다.
RNN은 이런 작업이 모두 필요 없습니다. RNN은 좋은 성능을 내기에 너무 단순합니다!!
심층 RNN
RNN을 여러개 쌓으면 심층 RNN(deep RNN)이 됩니다.
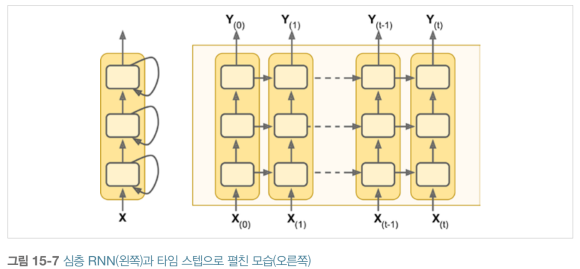
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20),
keras.layers.Dense(1)
])심층 RNN 간에는 모든 타임 스텝에 대한 출력을 보내야합니다.(return_sequences=True) 그렇지 않으면, 마지막 타임 스텝의 출력만 2D 배열로 출력되어서, 다음 순환 층이 3D 형태로 시퀀스를 받지 못해 작동할 수 없습니다.
내 생각: RNN 층 간에는 매 타임 스텝마다 타임 스텝에 따른 출력을 순환되므로 하나의 모듈처럼 생각할 수도 있는 것 같다.
또한, SimpleRNN 층은 보통 tanh 활성화 함수에서만 잘 작동해서, 다양한 활성화 함수를 사용할 수 있는 Dense 층을 마지막 층올 사용하는 것이 일반적입니다. 이는 훈련 속도도 높여줍니다.
여러 타임 스텝 앞을 예측하기
다음 스텝이 아닌 여러 타임 스텝 앞을 예측하려면 어떻게 해야할까요? 2가지 방법을 소개합니다.
1. 다음 스텝만 예측하는 모델의 출력을 다음 입력으로 추가해 다시 다음 값을 예측하는 방법이 있습니다.
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer="adam")
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))series = generate_time_series(1, n_steps + 10) # 배치 1세트, 60 time step
X_new, Y_new = series[:, :n_steps], series[:, n_steps:]
X = X_new
for step_ahead in range(10):
y_pred_one = model.predict(X[:, step_ahead:])[:, np.newaxis, :]
# model.predict(X[:, 0:])는 모든 배치의 time step 0~49까지 받아서 50번째 time step을 예측합니다.
# model.predict(X[:, 1:])는 모든 배치의 time step 1~50까지 받아서 51번째 time step을 예측합니다.
X = np.concatenate([X, y_pred_one], axis=1)
# 예측한 것과 X를 합쳐줍니다.
Y_pred = X[:, n_steps:]
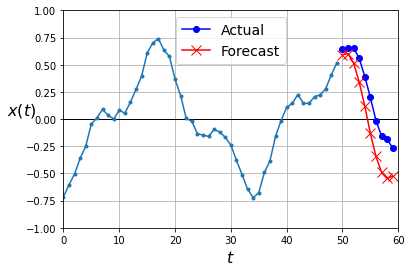
이는 선형 모델보다 MSE가 더 높아서 성능이 좋지 않습니다.
2. RNN을 훈련하여 다음 값 10개를 한 번에 예측할 수 있습니다. 같은 sequence-to-vector 모델을 사용하지만, 값을 1개가 아닌 10개를 출력합니다.
10개로 된 Target 데이터를 준비합니다.
series = generate_time_series(10000, n_steps + 10)
X_train, Y_train = series[:7000, :n_steps], series[:7000, -10:, 0]
X_valid, Y_valid = series[7000:9000, :n_steps], series[7000:9000, -10:, 0]
X_test, Y_test = series[9000:, :n_steps], series[9000:, -10:, 0]
# series.shape = (10000, 60, 1)
# X_train.shape = (7000, 50, 1)
# Y_train.shape = (7000, 10)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20),
keras.layers.Dense(10)
])
model.compile(optimizer='adam', loss='mse')
model.fit(X_train, Y_train, validation_data=(X_valid, Y_valid), epochs=20)
series = generate_time_series(1, n_steps+10)
# series(1, 60, 1) → X_new(1, 50, 1), Y_new(1, 10, 1)
X_new, Y_new = series[:, :50, :], series[:, -10:, :]
Y_pred = model.predict(X_new)[:, :, np.newaxis]
plot_multiple_forecasts(X_new, Y_new, Y_pred)MSE는 검증데이터에서 0.0098이 나왔습니다.
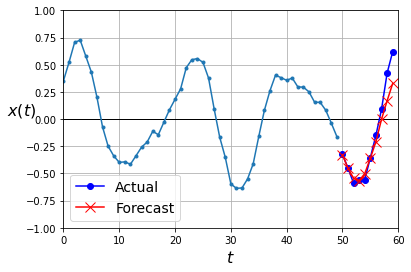
이 모델은 잘 작동하고 선형 모델보다 훨씬 좋습니다. 하지만 더 개선할 수 있습니다. 마지막 타임 스텝에서만 다음 값 10개를 예측하도록 모델을 훈련하는 대신 모든 타임 스텝에서 다음 값 10개를 예측하도록 모델을 훈련할 수 있습니다. 이는 sequenco-to-vector RNN에서 sequence-to-sequence RNN으로 바꾼다는 의미입니다.
즉, 타임 스텝 0에서 49까지를 기반으로 타임 스텝 50~ 59를 예측하는 것이 아니라, 타임 스텝 0에서 타임 스텝 1~10까지 예측하고, 그 다음 타임 스텝 1에서 타임 스텝 2~ 11까지 예측합니다. 마지막 타임 스텝에서는 타임 스텝 50~ 59까지 예측합니다. 이를 인과 모델(causal model)이라 합니다. 어떤 타임 스텝에서 예측할 때, 과거 타임 스텝만 볼 수 있습니다.
sequence-to-sequence 모델을 만들려면, 모든 타임 스텝에서 출력을 Dense 층에 적용해야합니다. 이런 목적을 위해 케라스는 TimeDistributed 층을 제공합니다. 이는 입력 [배치 크기, 타임 스텝 수, 입력 차원]을 [배치 크기 x 타임 스텝 수, 입력 차원]으로 크기를 바꿉니다. 이전 SimpleRNN의 유닛이 20개이므로 입력 차원은 20입니다. 마지막으로 출력 크기를 시퀀스로 되돌립니다. 즉, 출력을 [배치 크기 x 타임 스텝 수, 출력 차원]에서 [배치 크기, 타임 스텝 수, 출력 차원]으로 되돌립니다. Dense 층의 유닛이 10개 이므로 출력 차원은 10입니다. 사실 그냥 Dense로도 매 타임 스탭 시퀀스를 받을 수 있습니다.
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])타깃 데이터 Y가 현재 타임 스텝보다 10개의 앞선 출력을 담도록 준비합니다.
np.random.seed(42)
n_steps = 50
series = generate_time_series(10000, n_steps + 10)
X_train = series[:7000, :n_steps]
X_valid = series[7000:9000, :n_steps]
X_test = series[9000:, :n_steps]
Y = np.empty((10000, n_steps, 10))
for step_ahead in range(1, 10+1):
Y[..., step_ahead -1] = series[..., step_ahead:step_ahead + 50, 0]
# Y[:, 0:50, 0]에는 series[:, 1:50, 0]의 값들이 들어가 있다.
# Y[:, 0:50, 1]에는 series[:, 2:51, 0]의 값들이 들어가 있다.
# Y[:, 0, 0:10]에는 series[:, 1:10, 0]의 값이 들어있다.
# Y[:, 1, 0:10]에는 series[:, 2:11, 0]의 값이 들어있다.
Y_train = Y[:7000] # Y_train.shape = (7000, 50, 10)
Y_valid = Y[7000:9000]
Y_test = Y[9000:]훈련 시에는 매 타임 스텝의 출력이 필요하지만, 예측, 평가에는 마지막 타임 스텝의 출력만 사용하면 됩니다. 훈련을 위해 모든 출력에 걸쳐 MSE를 계산했고, 평가를 위해서 마지막 타임 스텝의 출력에 대한 MSE만 계산하는 사용자 정의 지표를 정의했습니다.
def last_time_step_mse(Y_true, Y_pred):
return keras.metrics.mean_squared_error(Y_true[:, -1], Y_pred[:, -1])
# Y_pred[:, -1] = Y_pred[:, -1, :], shape=(2000, 10)
model.compile(loss='mse', optimizer=keras.optimizers.Adam(lr=0.01), metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
'''
Epoch 1/20
219/219 [===========================] - 6s 20ms/step - loss: 0.0528 - last_time_step_mse: 0.0428
- val_loss: 0.0406 - val_last_time_step_mse: 0.0290
Epoch 2/20
219/219 [===========================] - 4s 19ms/step - loss: 0.0375 - last_time_step_mse: 0.0244
- val_loss: 0.0375 - val_last_time_step_mse: 0.0271
...
Epoch 20/20
219/219 [===========================] - 4s 18ms/step - loss: 0.0186 - last_time_step_mse: 0.0072
- val_loss: 0.0187 - val_last_time_step_mse: 0.0077
'''
검증 MSE로 0.0077을 얻었습니다. 이전 모델보다 훨씬 정확합니다. 이런 방식을 이전 모델과 결합할 수 있습니다. 이 RNN을 통해 다음 값 10개를 예측하고 이 값을 다시 입력 시계열에 연결할 수 있습니다. 이런 식으로 필요한 만큼 반복해 어떤 길이의 시퀀스도 생성할 수 있습니다. 장기간 예측하면 정확도가 떨어지겠지만, 16장에서 볼 음악, 텍스트를 생성하는 것에는 문제가 되지 않습니다.
TIP
시계열을 예측할 때, 오차 막대(error bar)를 사용하는 것이 유용합니다. 오차막대는 여러번 실행하여 얻은 결과의 범위를 말합니다. 이에 대한 효율적인 도구는 MC 드롭아웃입니다. 각 메모리 셀에 드롭아웃 층을 추가하여 입력, 은닉 상태를 드롭아웃합니다.
훈련이 끝난 후 새로운 시계열을 예측하기 위해 이 모델을 여러 번 사용해 각 타임 스텝에서 예측의 평균, 표준편차를 계산합니다.
긴 시계열에서는 간단한 RNN이 잘 동작하지 않는데, 그 이유와 대처 방안을 알아보겠습니다.
긴 시퀀스 다루기
RNN을 훈련하려면 많은 타임 스텝에 걸쳐 실행해야 합니다. 타임 스텝에 따라 펼친 RNN은 매우 깊은 네트워크가 됩니다. 이는 보통 심층 신경망처럼 그레디언트 소실, 폭주 문제로 이어질 수 있습니다.(상태 함수의 가중치에 대한 backpropagate를 해주려면 이전 타임 스텝에 대한 gradient들을 전부 계산해주어야한다.) 훈련이 오래 걸리거나 불안정할 수 있고, RNN이 긴 시퀀스를 처리할 때 입력의 첫 부분을 조금씩 잊어버릴 겁니다.(Vanishing Gradient)
불안정한 그레디언트 문제와 싸우기
불안정한 그레디언트 문제의 해결책은 심층 신경망에서와 같이 좋은 가중치 초기화, 빠른 옵티마이저, 드롭아웃 등을 사용할 수 있습니다.
RNN에 활성화 함수로 ReLU같은 수렴하지 않는 함수는 도움이 되지 않습니다. 경사 하강법이 첫 번째 타임 스텝에서 출력을 조금 증가시키는 방향으로 가중치를 업데이트 하면, 동일한 가중치가 모든 타임 스텝에 사용되어서 두 번째 타임 스텝, 세 번째 타임 스텝의 출력도 조금 증가할 것입니다. 이런 식으로 출력이 폭주합니다. tanh같은 수렴하는 활성화 함수는 이런 위험을 감소시킬 수 있습니다.
같은 방식으로 그레디언트 자체도 폭주할 수 있는데, 텐서보드로 그레디언트의 크기를 모니터링하고, 그레디언트 클리핑(gradient clipping)을 사용하는 것이 좋습니다.
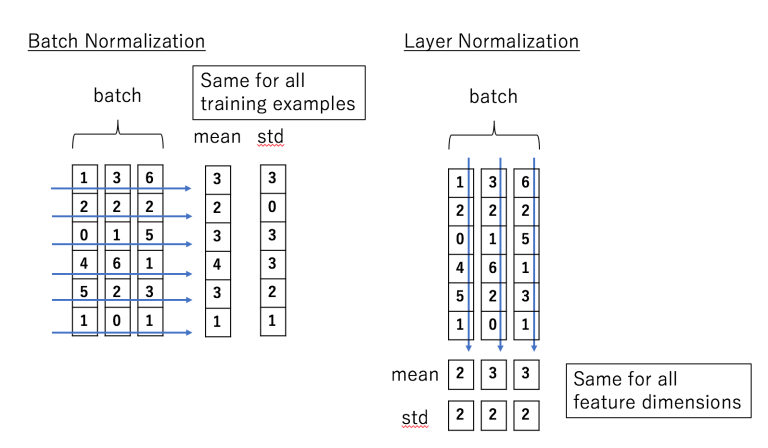
배치 정규화 층인 BatchNormalization 층은 입력에만, 즉 순환층 사이에 적용했을 때 아주 미세한 효과가 있습니다. RNN에 잘 맞는 다른 종류의 정규화는 층 정규화(layer normalization)입니다. 배치 정규화와 매우 비슷하지만, 배치 차원에서 정규화하는 대신 특성 차원에서 정규화합니다. 이는 샘플에 독립적으로 타임 스텝마다 동적으로 필요한 통계를 계산할 수 있다는 것입니다. 이는 훈련과 테스트에서 모두 동일한 방식으로 작동합니다. 훈련 세트의 모든 샘플에 대한 특성 통계를 추정하기 위해 지수 이동 평균이 필요하지 않습니다. 배치 정규화와 마찬가지로 층 정규화는 입력마다 하나의 스케일, 이동 파라미터를 학습합니다. RNN에서 층 정규화는 일반적으로 입력과 은닉 상태의 선형 조합 직후에 사용됩니다. 즉, 층 정규화는 샘플의 모든 피처에 대한 평균, 표준편차를 계산하는 것이다.
메모리 셀 안에 층 정규화를 구현하려면 사용자 정의 메모리 셀을 정의해야합니다.
class LNSimpleRNNCell(keras.layers.layer):
def __init__(self, units, activation='tanh', **kwargs):
super().__init__(**kwargs)
self.state_size = units
self.output_size = units
self.simple_rnn_cell = keras.layers.SimpleRNNCell(units, activation=None)
self.layer_norm = keras.layers.LayerNormalization()
self.activation = keras.activations.get(activation)
def call(self, inputs, states):
outputs, new_states = self.simple_rnn_cell(inputs, states)
norm_outputs = self.activation(self.layer_norm(outputs))
return norm_outputs, [norm_outputs]
call() 메서드가 2개의 매개변수를 받는 것을 제외하고는 일반적인 층입니다. 현재 타임 스텝의 inputs와 이전 타임 스텝의 은닉 states입니다. states 매개변수는 하나 이상의 텐서를 담은 리스트입니다.(여기서는 출력값인 하나의 텐서)
셀은 state_size, output_size 속성을 가져야합니다. 간단한 RNN은 유닛 개수와 동일합니다. 이 셀은 두 개의 결과를 반환합니다. 하나는 출력, 하나는 새로운 은닉 상태가 됩니다. (new_states는 SimpleRNNCell에서 출력과 동일해서 여기에서는 무시해도 괜찮습니다.)
사용자 정의 셀을 사용하려면 keras.layers.RNN 층을 만들어 이 셀의 객체를 전달하면 됩니다.
model = keras.models.Sequential([
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True,
input_shape=[None, 1]),
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
비슷하게 타임 스텝 사이에 드롭아웃을 적용하는 사용자 정의 셀을 만들 수 있지만, 케라스에서 제공하는 모든 순환층, 셀은 dropout 매개변수, recurrent_dropout 매개변수를 지원해서 따로 사용자 정의 셀을 만들 필요가 없습니다. 전자는 (타임 스텝마다) 입력에 적용하는 드롭아웃 비율을 정의합니다. 후자는 (타임 스텝마다) 은닉 상태에 대한 드롭아웃 비율을 정의합니다.
이러한 기법으로 불안정한 그레디언트 문제를 감소시킬 수 있습니다.
단기 기억 문제 해결하기
RNN을 거치면서 데이터가 변환되므로 일부 정보는 매 훈련 스텝 후 사라집니다. 어느 정도 시간이 지나면 RNN은 사실상 첫 번째 입력의 흔적을 가지고 있지 않습니다. 긴 문장을 번역할 때, 문장을 다 읽고 나면 앞 부분을 까먹는 현상이 발생하게됩니다. 이를 위해 LSTM 셀이 생겼습니다.
LSTM(long-short term memory) 셀
# 사용법 1
model = keras.models.Sequential([
keras.layers.LSTM(20, return_sequence=True, input_shape=[None, 1]),
keras.layers.LSTM(20, return_sequence=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
# 사용법 2
model = keras.models.Sequential([
keras.layers.RNN(keras.layers.LSTMCell(20), return_sequences=True,
input_shape=[None, 1]),
keras.layers.RNN(keras.layers.LSTMCell(20), return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
LSTM 층(사용법1)은 GPU에서 실행할 때, 최적화된 구현을 실행하므로 일반적으로 선호됩니다.
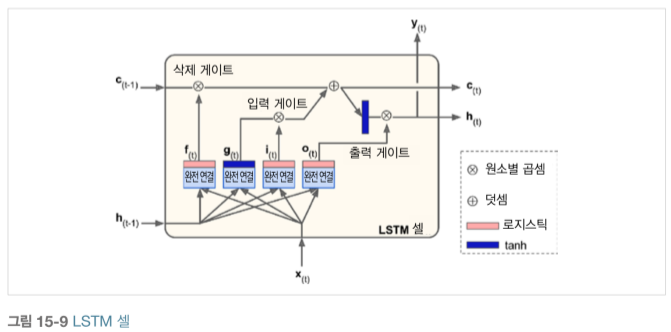
LSTM은 상태가 단기 상태(short-term state) $h_{\left(t\right)}$와 장기 상태(long-term state) $c_{\left(t\right)}$로 나뉩니다.
장기 기억 $c_{\left(t-1\right)}$은 삭제 게이트(forget gate)를 지나 일부 기억을 잃고, 덧셈 연산으로 입력 게이트(input gate)에서 선택한 새로운 기억 일부를 추가합니다. 이를 장기 기억으로 보내고, 복사한 값을 tanh 함수로 전달한 후 출력 게이트(output gate)로 일부 결과를 필터링한 후 단기 상태$h_{\left(t\right)}$를 만듭니다.
현재 입력 벡터 $X_{\left(t\right)}$와 이전 단기 상태 $h_{\left(t-1\right)}$는 4개의 다른 완전 연결 층에 주입됩니다. 이 층은 모두 다른 목적을 가집니다.
- 주 층은 $g_{\left(t\right)}$입니다. 이 층은 현재 입력 $X_{\left(t\right)}$과 이전 단기 상태 $h_{\left(t-1\right)}$를 분석하는 일반적인 역할을 담당합니다. 기본 셀에서는 이 층만 존재하며 $y_{\left(t\right)}$와 $h_{\left(t\right)}$로 출력됩니다. LSTM에서는 이 출력이 곧바로 나가지 않고 대신 장기 상태로 갈 부분이 저장됩니다.(나머지는 버립니다.)
세 개의 다른 층은 게이트 제어기(gate controller)입니다. 이들은 logistic 활성화 함수를 사용해 출력이 0~1입니다. 이들의 출력은 원소별 곱셈 연산으로 주입되어 0을 출력하면 게이트를 닫고, 1을 출력하면 게이트를 엽니다.
- $f_{\left(t\right)}$가 제어하는 삭제 게이트는 장기 상태의 어느 부분이 삭제되어야 하는제 제어합니다.
- $i_{\left(t\right)}$가 제어하는 입력 게이트는 $g_{\left(t\right)}$의 어느 부분이 장기 상태에 더해져야 하는지 제어합니다.
- $o_{\left(t\right)}$가 제어하는 출력 게이트는 장기 상태의 어느 부분을 읽어서 현재 타임 스텝의 $h_{\left(t\right)}$, $y_{\left(t\right)}$로 출력해야하는지 제어합니다.
LSTM은 중요한 입력을 장기 상태에 저장하고 이를 필요할 때마다 추출합니다. LSTM 셀은 시계열, 긴 텍스트, 오디오 등 장기 패턴을 잡아내는 데 놀라운 성과를 냅니다.
[LSTM 계산식]
$$i_{\left(t\right)}=δ\left(W_{xi}^TX_{\left(t\right)}+W_{hi}^Th_{\left(t-1\right)}+b_i\right)$$
$$f_{\left(t\right)}=δ\left(W_{xf}^TX_{\left(t\right)}+W_{hf}^Th_{\left(t-1\right)}+b_f\right)$$
$$o_{\left(t\right)}=δ\left(W_{xo}^TX_{\left(t\right)}+W_{ho}^Th_{\left(t-1\right)}+b_o\right)$$
$$g_{\left(t\right)}=\tanh \left(W_{xg}^TX_{\left(t\right)}+W_{hg}^Th_{\left(t-1\right)}+b_g\right)$$
$$c_{\left(t\right)}=f_{\left(t\right)}\otimes c_{\left(t-1\right)}+i_{\left(t\right)}\otimes g_{\left(t\right)}$$
$$y_{\left(t\right)}=h_{\left(t\right)}=o_{\left(t\right)}\otimes \tanh \left(c_{\left(t\right)}\right)$$
- $W_{xi},\ W_{xf},\ W_{xo},\ W_{xg}$는 입력 벡터 $X_{\left(t\right)}$에 각각 연결된 4개 층의 가중치 행렬입니다.
- $W_{hi},\ W_{hf},\ W_{ho},\ W_{hg}$는 이전 단기 상태 $h_{\left(t-1\right)}$에 연결된 4개 층의 가중치 행렬입니다.
- $b_i,\ b_f,\ b_o,\ b_g$는 4개 층에 대한 각 편향입니다. 텐서플로에서 $b_f$는 1로 채워진 벡터로 초기화해서 훈련 초기에 모든 것이 망각되는 것을 방지합니다.
핍홀 연결
일반 LSTM 셀에서 게이트 제어기들은 $X_{\left(t\right)}$와 $h_{\left(t-1\right)}$만 볼 수 있습니다. 게이트 제어기에도 장기 상태를 조금 노출시켜 더 많은 문맥을 감지하게 만들고 싶었습니다. 그래서 만들어진게 핍홀 연결(peephole connection)이 추가된 LSTM 변종입니다.
이는 $c_{\left(t-1\right)}$을 $f_{\left(t\right)},\ i_{\left(t\right)}$에 입력으로 추가합니다. 그리고 $c_{\left(t\right)}$를 $o_{\left(t\right)}$에 입력으로 추가합니다. 이는 성능을 향상하는 경우가 많지만 어떤 종류의 작업이 좋아지는지 명확하지 않습니다.
케라스에서는 실험적으로 tf.keras.experimental.PeepholeLSTMCell 층이 있습니다. keras.layers.RNN 층의 생성자에 PeepholeLSTMCell을 전달하여 만들 수 있습니다.
GRU 셀
게이트 순환 유닛(gated recurrent unit) GRU 셀은 LTSM 셀의 간소화된 버전이고 유사하게 작동합니다.

- 두 상태 벡터가 하나의 상태 벡터 $h_{\left(t\right)}$로 합쳐졌습니다.
- 하나의 게이트 제어기 $z_{\left(t\right)}$가 삭제 게이트, 입력 게이트를 모두 제어합니다. 게이트 제어기가 1을 출력하면 삭제 게이트기가 열리고(=1) 입력 게이트가 닫힙니다. (1-1=0) 다시 말해, 기억이 저장될 때마다 저장될 위치가 먼저 삭제됩니다.
- 출력 게이트 없이 전체 상태 벡터가 매 타임 스텝마다 출력되는데, 이전 상태의 어느 부분이 주 층($g_{\left(t\right)}$)에 노출될지 제어하는 새로운 게이트 제어기 $r_{\left(t\right)}$가 있습니다.
[GRU 계산]
$$z_{\left(t\right)}=δ\left(W_{xz}^TX_{\left(t\right)}+W_{hz}^Th_{\left(t-1\right)}+b_z\right)$$
$$r_{\left(t\right)}=δ\left(W_{xr}^TX_{\left(t\right)}+W_{hr}^Th_{\left(t-1\right)}+b_r\right)$$
$$g_{\left(t\right)}=\tanh \left(W_{xg}^TX_{\left(t\right)}+W_{hg}^T\left(r_{\left(t\right)}\otimes h_{\left(t-1\right)}\right)+b_g\right)$$
$$h_{\left(t\right)}=z_{\left(t\right)}\otimes h_{\left(t-1\right)}+\left(1-z_{\left(t\right)}\right)\otimes g_{\left(t\right)}$$
케라스는 keras.layers.GRU 층을 제공합니다. LSTM과 GRU 층은 100 타임 스텝 이상의 시퀀스에서 장기 패턴을 학습하는 데 어려움이 있습니다. 이 문제를 해결하는 한 가지 방법은 1D 합성곱 층을 사용해 입력 시퀀스를 짧게 줄이는 것입니다.
1D 합성곱 층을 사용해 시퀀스 처리하기
1D 합성곱 층이 몇 개의 커널을 시퀀스 위로 슬라이딩 하여 1D 특성 맵을 출력합니다. 10개의 커널을 사용하면 이 층의 출력은 10개의 1차원 시퀀스로 구성됩니다. 또는, 이 출력을 10차원 시퀀스 하나로 볼 수 있습니다.
이는 1D 합성곱 층과 순환 층을 섞어서 신경망을 구성할 수 있다는 뜻입니다. stride=1, 'same' 패딩으로 1D 합성곱 층을 사용하면 출력 시퀀스의 길이가 입력 시퀀스와 같습니다. 하지만, 'valid' 패딩과 stride>1일 경우 출력 시퀀스는 입력 시퀀스보다 짧아집니다.
model = keras.models.Sequential([
keras.layers.Conv1D(filters=20, kernel_size=4, strides=2,
padding='valid', input_shape=[None, 1]),
keras.layers.GRU(20, return_sequence=True),
keras.layers.GRU(20, return_sequence=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss='mse', optimizer='adam', metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train[:, 3::2], epochs=20,
validation_data=(X_valid, Y_valid[:, 3::2]))
valid 패딩이므로 커널 크기에 맞는 입력을 받을 때까지 출력하지 않습니다.(커널 크기가 4이므로 합성곱 층의 첫 출력은 0~3까지의 타임 스텝으로 만들어집니다.) 따라서 처음 세 개의 타임 스텝을 버리고, 두 배로 다운샘플합니다.
이 모델은 훈련 후 평가하면 지금까지 가장 좋은 모델일 것입니다. 합성곱 층은 정말 도움이 됩니다. 사실 순환 층을 제거하고 1D 합성곱 층만 사용할 수도 있습니다.
WAVENET
WaveNet의 구조에 대한 간략한 설명을 해보겠습니다. 실제 논문은 아래보다 더 많은 층과 복잡한 구조를 가졌습니다.
WaveNet은 층마다 팽창 비율(dilation rate)을 2배로 늘리는 1D 함성곱 층을 쌓았습니다.
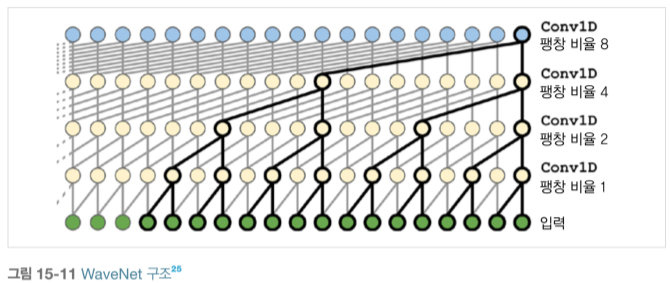

첫 번째 합성곱 층이 2개의 타임 스탭만 봅니다. 다음 층은 3개의 타임 스텝을 보고(즉, 수용장 길이가 4개의 타임 스텝이 됩니다.), 다음은 8개의 타임 스텝을 보는 식입니다. 이런 식으로 하위 층은 단기 패턴을 학습하고 상위 층은 장기 패턴을 학습합니다.
살짝 희미한 뉴런이 값이 0인 팽창된 뉴런인 듯 이전 + 현재층의 팽창 비율 값들이 더해진 만큼 늘어남
WaveNet 논문에서는 팽창 비율이 1, 2, 4, 8, .., 256, 512인 동일한 층 10개를 따로 그룹지어 쌓았고, 이는 1,024 크기의 커널 한 개로 이루어진 매우 효율적인 합성곱 층처럼 동작합니다. 각 층의 이전 팽창 비율과 동일한 개수의 0을 입력 시퀀스의 왼쪽 패딩으로 추가해 네트워크를 통과하는 시퀀스의 길이를 동일하게 만들었습니다. dilation_rate*(kernel_size-1)만큼 왼쪽에 0을 패딩으로 추가합니다. 이 패딩 방식은 padding='causal'로 지정합니다.
model = keras.models.Sequential()
model.add(keras.layers.InputLayer(input_shape=[None, 1]))
for rate in (1, 2, 4, 8)*2:
model.add(keras.layers.Conv1D(filters=20, kernel_size=2, padding='causal',
activation='relu', dilation_rate=rate))
model.add(keras.layers.Conv1D(filters=10, kernel_size=1))
model.compile(loss='mse', optimizer='adam', metrcis=[last_time_step_mse])
history = model.fit(X_train, y_train, epochs=20,
validation_data = (X_valid, Y_valid))
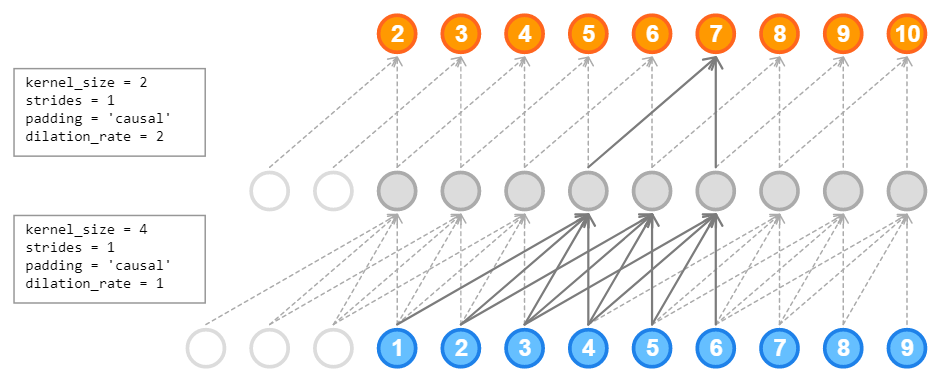
패딩을 'causal'로 지정해야 합성곱이 예측을 할 때, 미래의 시퀀스(다음 순서의 타임 스텝)를 훔쳐보지 않습니다. 이는 입력 왼쪽에 0을 알맞게 패딩하고 'valid' 패딩을 사용하는 것과 같습니다. 층에 추가한 padding 덕분에 모든 합성곱 층은 입력 시퀀스와 동일한 길이의 시퀀스를 출력합니다. 그리고 팽창 비율 1, 2, 4, 8의 층을 추가하고 다시 팽창 비율 1, 2, 4, 8의 층을 추가합니다. 마지막 출력층으로 크기가 1인 필터 10개를 사용하고 활성화 함수가 없는 합성곱 층을 사용합니다
첫 번째 합성곱 층의 가중치는 1(입력 채널)*2(커널사이즈)*20(커널 개수)+20(편향) = 60개의 가중치를 가집니다. 다음 층부터는 20*2*20+20 = 820개의 가중치를 갖습니다. 마지막 층은 20*1*10 +10 = 210개의 가중치를 갖습니다.
WaveNet은 매우 긴 시퀀스를 다룰 수 있습니다. 이 모델은 한 번 사용해 한 번에 하나의 음악 오디오 샘플을 생성했습니다. 오디오 1초에 수만 개의 타임 스텝이 포함될 수 있기 때문에 이 능력은 매우 놀랍습니다. 즉, 수용 범위가 넓어집니다.
출처: 핸즈 온 머신러닝 2판
사진 출처: 핸즈 온 머신러닝 2판
'핸즈온 머신러닝 2판' 카테고리의 다른 글
| 17장 오토인코더와 GAN을 사용한 표현 학습과 생성적 학습 (2) | 2022.02.03 |
|---|---|
| 16장 RNN과 어텐션을 사용한 자연어 처리 (1) | 2022.01.26 |
| 14장 합성곱 신경망을 사용한 컴퓨터 비전 (0) | 2022.01.15 |
| 13장 텐서플로에서 데이터 적재와 전처리하기 (0) | 2022.01.10 |
| 12장 텐서플로를 사용한 사용자 정의 모델과 훈련 (0) | 2022.01.04 |