배운 내용
- XGBoost
- DataFrame.describe()
- Series.fillna() or DataFrame.fillna()
- Series.replace()
- plot_importance()
- LightGBM
- GridSearchCV
분류 실습 - 캐글 산탄데르 고객 만족 예측
산탄데르 은행이 370개의 피처로 주어진 데이터 세트 기반에서 고객 만족 여부를 예측하는 것입니다. 클래스 레이블 명은 TARGET이며, 이 값이 1이면 불만족, 0이면 만족한 고객입니다. 모델의 성능 명가는 ROC-AUC로 평가합니다. 대부분 만족이고, 불만족인 데이터는 일부일 것이기 때문입니다. 데이터는 아래의 링크를 통해 내려받을 수 있습니다.
https://www.kaggle.com/c/santander-customer-satisfaction/data
Santander Customer Satisfaction | Kaggle
www.kaggle.com
데이터 전처리
학습 데이터를 로딩하고 데이터의 shape과 일부 데이터를 출력합니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
cust_df = pd.read_csv('/content/drive/MyDrive/military/santander/train.csv', encoding='latin-1')
print('dataset shape:', cust_df.shape)
cust_df.head(3)
'''
dataset shape: (67142, 371)
결과2
'''
cust_df.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 67142 entries, 0 to 67141
Columns: 371 entries, ID to TARGET
dtypes: float64(218), int64(153)
memory usage: 190.0 MB
'''float 형 218개, int형 153개가 피처를 이룹니다. 데이터에서 만족, 불만족의 비율을 살펴보겠습니다.
print(cust_df['TARGET'].value_counts())
unsatisfied_cnt = cust_df[cust_df['TARGET'] == 1].TARGET.count()
total_cnt = cust_df.TARGET.count()
print('unsatisfied 비율은 {0:.2f}'.format((unsatisfied_cnt/total_cnt)))
'''
0.0 64511
1.0 2630
Name: TARGET, dtype: int64
unsatisfied 비율은 0.04
'''
Series.fillna()
null 데이터를 피처의 평균으로 바꿔주고, null 데이터는 0으로 바꿔줍니다.
for key in cust_df.keys():
null_d = cust_df[key]
cust_df[key] = null_d.fillna(null_d.mean())
cust_df['TARGET'] = cust_df['TARGET'].fillna(0)
print(cust_df['TARGET'].value_counts())
'''
0.0 64512
1.0 2630
'''
DataFrame.describe()
각 피처의 값 분포를 간단히 확인해보겠습니다.
cust_df.describe()
'''
결과3
'''var3 칼럼을 보면 값 편차가 심한 -999999 값이 min값입니다. 아마 NaN이나 특정 예외 값을 그렇게 설정했을 것입니다. ID 값은 단순히 식별자 역할이므로 피처를 드롭하고 train, test 데이터 세트로 분리해 저장하겠습니다.
print(cust_df.var3.value_counts()[:10])
'''
2 65494
8 120
-999999 102
9 101
3 96
1 91
7 87
13 86
4 77
12 72
Name: var3, dtype: int64
'''
Series.replace()
-999999값이 102개나 되므로, 이를 가장 값이 많은 2로 변환하겠습니다.
cust_df['var3'].replace(-999999, 2, inplace=True)
cust_df.drop('ID', axis=1, inplace=True)
# 피처 세트와 레이블 세트 분리. 레이블 칼럼은 DataFrame의 맨 마지막에 위치해 칼럼 위치 -1로 분리
X_features = cust_df.iloc[:, :-1]
y_labels = cust_df.iloc[:, -1]
print('피처 데이터 shape:{0}'.format(X_features.shape))
'''
피처 데이터 shape:(67142, 369)
'''from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_features, y_labels,\
test_size=0.2, random_state=0, stratify=y_labels)
train_cnt = y_train.count()
test_cnt = y_test.count()
print('학습 세트 Shape:{0}'.format(X_train.shape))
print('학습 세트 레이블 값 분포 비율')
print(y_train.value_counts()/train_cnt)
print('\n테스트 세트 Shape:{0}'.format(X_test.shape))
print('테스트 세트 레이블 값 분포 비율')
print(y_test.value_counts()/test_cnt)
'''
학습 세트 Shape:(53713, 369)
학습 세트 레이블 값 분포 비율
0.0 0.960829
1.0 0.039171
Name: TARGET, dtype: float64
테스트 세트 Shape:(13429, 369)
테스트 세트 레이블 값 분포 비율
0.0 0.960831
1.0 0.039169
Name: TARGET, dtype: float64
'''비대칭한 데이터 세트이므로 클래스인 Target값이 train, test 데이터 세트에서 균형 있게 분할됐는지 확인해야합니다. stratify=y_labels를 주어서, X_train, X_test 모두 원본 데이터와 유사하게 전체 데이터의 4% 정도의 불만족 값(값 1)으로 만들어졌습니다.
XGBoost 모델 학습과 하이퍼 파라미터 튜닝
먼저 XGBClassifier를 기반으로 학습을 수행하고, ROC AUC로 평가해보겠습니다. 테스트 데이터를 이번에도 평가 데이터로 사용할 것인데, 테스트 데이터를 학습에 사용하면 과적합의 가능성을 증가시킨다는 점 다시 한 번 명심해야하겠습니다.
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
# n_estimators는 500으로, random state는 예제 수행 시마다 동일 예측 결과를 위해 설정.
xgb_clf = XGBClassifier(n_estimators=500, random_state=156)
# 성능 평가 지표를 auc로, 조기 중단 파라미터는 100으로 설정하고 학습 수행.
# eval_set=[(train),(test)]는 학습은 train으로 평가는 test로 하라는 뜻
# eval_set=[(test)]는 test로 평가를 하라는 의미, 뜻이 더 명확함.
xgb_clf.fit(X_train, y_train, early_stopping_rounds=100,\
eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)])
# 테스트 데이터로 예측
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:, 1], average='macro')
print('ROC AUC: {0:.4f}'.format(xgb_roc_score))
'''
ROC AUC: 0.8494
'''
이번엔 XGBoost의 하이퍼 파라미터 튜닝을 수행해보겠습니다. 칼럼의 개수가 많으므로 과적합 가능성을 가정하고, max_depth, min_child_weight, colsample_bytree 하이퍼 파라미터만 튜닝 대상으로 하겠습니다. 학습 시간이 오래 걸리는 ML 모델의 경우 2~3개의 하이퍼 파라미터를 먼저 튜닝한 한 후 다시 1~2개의 다른 파라미터를 튜닝하는 것입니다.
수행시간이 오래 걸리므로 n_estimators는 100으로, early_stopping_rounds는 30으로 줄여 테스트 해보겠습니다.
from sklearn.model_selection import GridSearchCV
# 하이퍼 파라미터 테스트의 수행 속도를 향상시키기 위해 n_estimators를 100으로 감소
xgb_clf = XGBClassifier(n_estimators=100)
params = {'max_depth':[5, 7], 'min_child_weight':[1, 3],\
'colsample_bytree':[0.5, 0.75]}
# cv는 3으로 지정
gridcv = GridSearchCV(xgb_clf, param_grid=params, cv=3)
gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric="auc",\
eval_set=[(X_test, y_test)])
print('GridSearchCV 최적 파라미터:', gridcv.best_params_)
xgb_roc_score = roc_auc_score(y_test, gridcv.predict_proba(X_test)[:, 1], average='macro')
print('ROC AUC: {0:.4f}'.format(xgb_roc_score))
'''
GridSearchCV 최적 파라미터: {'colsample_bytree': 0.5, 'max_depth': 7, 'min_child_weight': 1}
ROC AUC: 0.8505
'''앞에서 구한 최적 하이퍼 파라미터를 기반으로 learning_ratesms 0.02로, reg_alpha=0.03을 추가하겠습니다. n_estimator를 1000으로 늘리고, 다시 XGBClassifier를 학습시켜 ROC AUC를 구해보겠습니다.
# n_estimators는 1000으로 증가시키고, learning_rate=0.02로 감소, reg_alpha=0.03으로 추가함.
xgb_clf = XGBClassifier(n_estimators=1000, random_state=156, learning_rate=0.02\
,max_depth=7, min_child_weight=1, colsample_bytree=0.75, reg_alpha=0.03)
# 성능 평가 지표를 auc로, 조기 중단 파라미터 값은 200으로 설정하고 학습 수행.
xgb_clf.fit(X_train, y_train, early_stopping_rounds=200,\
eval_metric="auc", eval_set=[(X_test, y_test)])
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:, 1], average='macro')
print('Roc AUC: {0:.4f}'.format(xgb_roc_score))
'''
Roc AUC: 0.8498
'''하이퍼 파라미터를 1~2개 더 튜닝했더니, AUC가 오히려 더 낮아졌습니다. 부스팅 계열 뿐 아니라 앙상블 계열 알고리즘은 하이퍼 파라미터 튜닝으로 성능 수치 개선이 급격히 되지는 않습니다. 기본적으로 앙상블 계열은 잡음에 강하기 때문입니다. XGBoost가 GBM을 기반으로 하기 때문에 수행시간이 긴 단점이 있습니다.
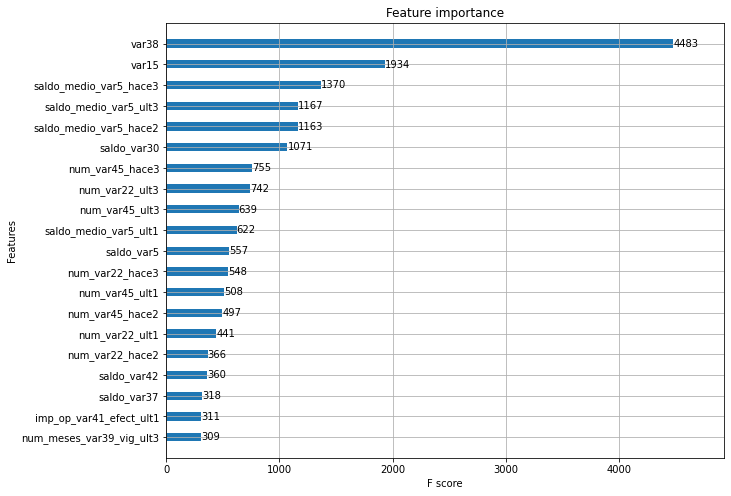
plot_importance()
튜닝된 모델의 각 피처의 중요도를 그려보겠습니다.
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(1, 1, figsize=(10, 8))
plot_importance(xgb_clf, ax=ax, max_num_features=20, height=0.4)
'''
결과4
'''
LightGBM 모델 학습과 하이퍼 파라미터 튜닝
LightGBM으로 학습을 수행하고 ROC-AUC를 측정해보겠습니다. 앞의 XGBoost 예제와 동일하게 파라미터를 설정하겠습니다.
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators=500)
evals = [(X_test, y_test)]
lgbm_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="auc",\
eval_set=evals, verbose=True)
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:, 1], average='macro')
print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))
'''
ROC AUC: 0.8451
'''확실히 XGBoost보다 학습 시간이 단축됐습니다. GridSearchCV로 하이퍼 파라미터를 튜닝하겠습니다. 튜닝 대상은 num_leaves, max_depth, min_child_samples, subsample 입니다.
from sklearn.model_selection import GridSearchCV
# 하이퍼 파라미터 테스트의 수행 속도를 향상시키기 위해 n_estimators=200으로 설정
lgbm_clf = LGBMClassifier(n_estimators=200)
params ={
'num_leaves': [32, 64],
'max_depth': [128, 160],
'min_child_samples': [60, 100],
'subsample': [0.8, 1]
}
# cv는 3으로 지정
gridcv = GridSearchCV(lgbm_clf, param_grid=params, cv=3)
gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric="auc",\
eval_set=[(X_test, y_test)])
print('GridSearchCV 최적 파라미터:', gridcv.best_params_)
lgbm_roc_score = roc_auc_score(y_test, gridcv.predict_proba(X_test)[:, 1], average='macro')
print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))
'''
GridSearchCV 최적 파라미터: {'max_depth': 128, 'min_child_samples': 60,
'num_leaves': 64, 'subsample': 0.8}
ROC AUC: 0.8457
'''최적화된 파라미터를 적용해 다시 학습시켜 ROC-AUC를 측정해보겠습니다.
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=64, subsample=0.8,\
minchild_samples=60, max_depth=128)
evals = [(X_test, y_test)]
lgbm_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric='auc', eval_set=evals,\
verbose=True)
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:, 1], average='macro')
print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))
'''
ROC AUC: 0.8434
'''피처 중요도를 시각화해보겠습니다.
from lightgbm import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(1, 1, figsize=(10, 8))
plot_importance(lgbm_clf, ax=ax, max_num_features=20)
'''
결과5
'''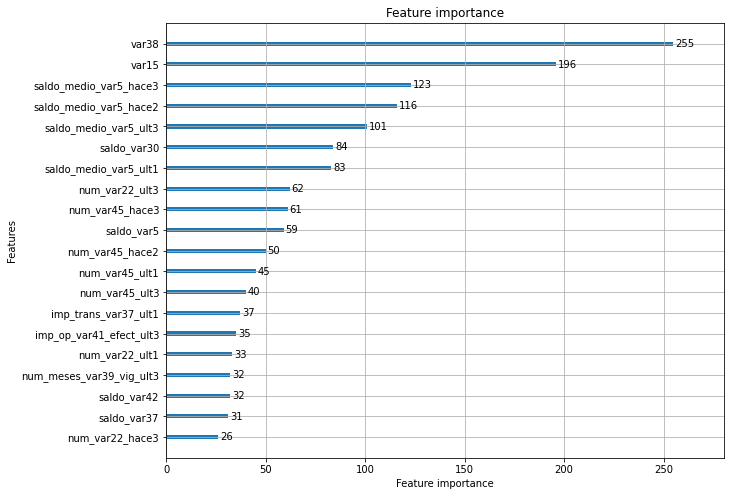
LightGBM의 피처 중요도가 XGBoost와 유사함을 알 수 있습니다.
출처: 파이썬 머신러닝 완벽 가이드(권철민)
'파이썬 머신 러닝 완벽 가이드' 카테고리의 다른 글
| 분류 - 스태킹 앙상블 (0) | 2021.11.16 |
|---|---|
| 분류 실습 - 캐글 신용카드 사기 검출 (0) | 2021.11.14 |
| 분류 (0) | 2021.11.06 |
| 피마 인디언 당뇨병 예측 (0) | 2021.11.05 |
| 평가 (0) | 2021.10.27 |